|
Elite Member
  加入日期: Nov 2004 您的住址: 北平西路3號
文章: 4,614
|
引用:
改名叫X4不就得了 這個架構跟OPTERON新版的架構又有些不同 難道說OPTERON跟ATHOLON64分道揚鑣了 以後應該就不會再有少一隻腳的OPTERON了 |
||||||||
 2006-05-17, 09:10 PM
#21
2006-05-17, 09:10 PM
#21
|


|
|
Senior Member
 加入日期: Jul 2002 您的住址: 光碟托盤
文章: 1,495
|
引用:
512KB L2 per core |
|||
|
2006-05-17, 10:04 PM
#22
|
|
|
Senior Member
加入日期: Jul 2002 您的住址: 光碟托盤
文章: 1,495
|
引用:
latency 太高 L3 專用 引用:
你確定用2 Level average latency 就一定會比3 level 好??? computer architecture 有讀熟嗎?? |
||
|
2006-05-17, 10:09 PM
#23
|
|
|
Senior Member
加入日期: Jul 2002 您的住址: 光碟托盤
文章: 1,495
|
引用:
OO loads 就差很多了 還有 single cycle throughput SIMD DP FP 改好的memory controler 也會差不少 |
|
|
2006-05-17, 10:12 PM
#24
|
|
|
Power Member
加入日期: Mar 2003 您的住址: 台北
文章: 597
|
引用:
你指的應該是130nm L2 1M的k8 L2 cache所佔die面積超過核心吧 但是我已經很明確的告訴你 90nm Rev.E Die size 199平方釐米 L2佔81平方釐米 90nm Rev.F Die size 220平方釐米 L2佔77平方釐米 可見製程縮小對於縮小cache應該是有較大助益的 所以光用比例來猜L2大大縮小有點不合理 至於多核心share cache問題 我想除了頻寬share之外 控制存取的困難度上升造成的latency增加也是一個關鍵 就目前看到的 IBM power6和intel Itanic 2都將用deditcated L2+share L3 而非share L2 我想這些都是trade-off的問題 |
|
|
2006-05-17, 10:50 PM
#25
|
|
|
Elite Member

加入日期: Aug 2001
文章: 12,393
|
 Realworld上David Kanter整理的比較詳細的detail: 0. Native quad core 1. Hypertransport up to 5.2GT/s 2. Better coherency 3. Private L2, shared L3 cache that scales up. 4. Separate power planes and pstates for north bridge and CPU 5. 128b FPUs - see 14,15 6. 48b virtual/physical addressing and 1GB pages 7. Support for DDR2, eventually DDR3 8. Support for FBD1 and 2 eventually 9. I/O virtualization and nested page tables 10. Memory mirroring, data poisoning, HT retry protocol support 11. 32B instead of 16B ifetch 12. Indirect branch predictors 13. OOO load execution - similar to memory disambiguation 14. 2x 128b SSE units 15. 2x 128b SSE LDs/cycle 16. Several new instructions Coprocessors: media processing JVM/CLR acceleration TOE, XML or SSL processing |
|
2006-05-18, 12:11 AM
#26
|
|
|
Major Member
加入日期: Sep 2004 您的住址: 木柵動物園
文章: 293
|
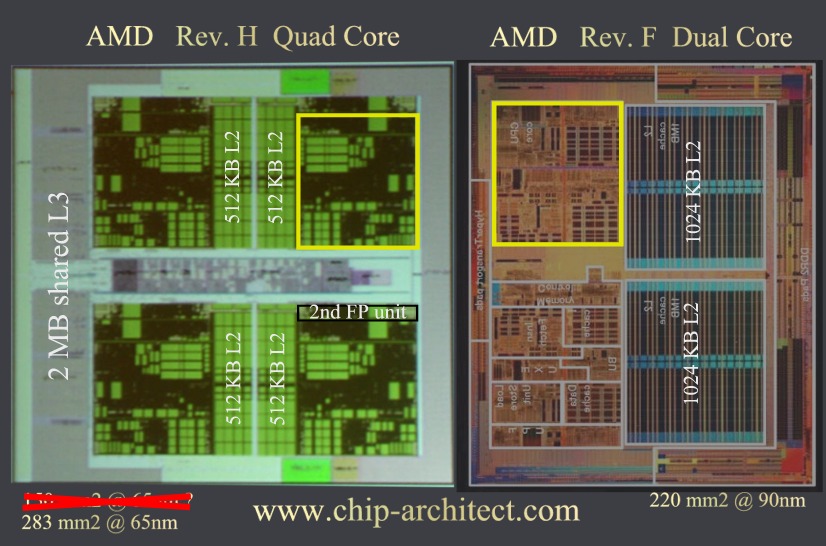
以比例來看,AMD 似乎把 Rev. G 512MB L2 cache 做得比 Rev. F 1MB 一半還小多了,比以前進步多了,至少成本降低不少。
不過老實講 shared L3 cache 只有 2MB 感覺有點太少了(dedicated L2 512MB*4 就已經 2MB 了),應該要有 4MB 的版本。 我想應該還是用 SRAM 尚未用到 Z-RAM,感覺如果用 Z-RAM 提高到 4~8MB 比較理想,雖然 latency 可能比較高,但畢竟 512MB L2 cache 快取命中率已經夠高了,Z-RAM 用來提高能 cache 的 workset 也夠讓許多 benchmark 提升不少。像 Power5 就有巨大的 36MB L3 cache (DRAM)。 至於 on-die memory controller 似乎還是一樣是 dual-channel,沒有做到 quad-channel,或是兩個 dual-channel。 老實說我覺得 dedicated L2 + shared L3 cache 是不錯的 trade-off,解決了 shared L2 cache 在 quad-core 面臨的 latency 與 four-port 設計上的問題,導致的性能瓶頸,dedicated L2 使得每個核心有自己高速的 L2 cache,shared L3 cache 又補足不能動態 balanced 的問題。只是 2MB shared L3 cache 有點少,最好能夠多一點,尤其是用 ZRAM 達到 4MB 以上。 從 11. 與 15. 點看來,L2 cache witdh 可能提升到 256bit 了。 多一個 FPU 單元,在 SSE 與 x87 性能似乎都增強不少,可能如同 INQ 說的達到 1.5 倍。 在 IPC 上,3, 11, 12 與 13 應該能有一些提升。 k8L 雖然在省電上進步不少,可以獨立調整 P-state 與 C-state,但似乎還是不能像 core 2 一樣動態的關閉 cache,可能是因為 exclusive cache 無法做到吧? 6, 9, 10 大概只會在 supercomputer 與 high-end server 上有很大的幫助。 第 1, 2, 3 點可能對於 8P~32P server 有不小的幫助。 |
|
2006-05-18, 01:38 AM
#27
|
|
|
Major Member
加入日期: May 2002
文章: 129
|
引用:
這時候CPU2應該是要想辦法把CPU1的該DATA抓到CPU2吧 否則DATA專一性可能不同 (若CPU1對該DATA有做運算) |
|
|
2006-05-18, 02:10 AM
#28
|
|
|
Major Member
加入日期: May 2002
文章: 129
|
引用:
嗯嗯 L2共享也有些BUS使用上的問題 CPU2使用L2時其他CPU不能使用 CPU越多的時候這問題會更嚴重吧 共不共享都是要評量的 沒有哪種架構一定完全都是優點沒缺點的 |
|
|
2006-05-18, 02:21 AM
#29
|
|
|
*停權中*
加入日期: Dec 2004
文章: 529
|
引用:
...................  |
|
|
2006-05-18, 02:23 AM
#30
|
|








