|
Senior Member
 加入日期: Mar 2004 您的住址: 長沙
文章: 1,365
|
鋪平未來之路:AMD顯卡架構轉換深度解密
消息來源
Radeon HD 6900系列終於發佈了,不過頂著全新架構的光環,實際性能卻並沒有很多人想像得那麼好。難道真是新架構如此不夠力?其實說白了這才是一次真真正正的過渡,AMD以此為試驗品,正在為未來做著新的準備。 要理解AMD為什麼使用VLIW4 4D式流處理器架構設計,首先必須理解AMD為什麼使用VLIW5 5D式流處理器架構設計,而要回答後邊這個問題,又必須回到更遙遠的DX9時代,種子早在那個時候就已經埋下。 VLIW:超長指令字串(Very long instruction word),指的是一種被設計為可以利用指令級並行(ILP)優勢的CPU體系結構。一個按照順序執行指令的非超標量處理器不能充分利用處理器的資源,有可能導致低性能。 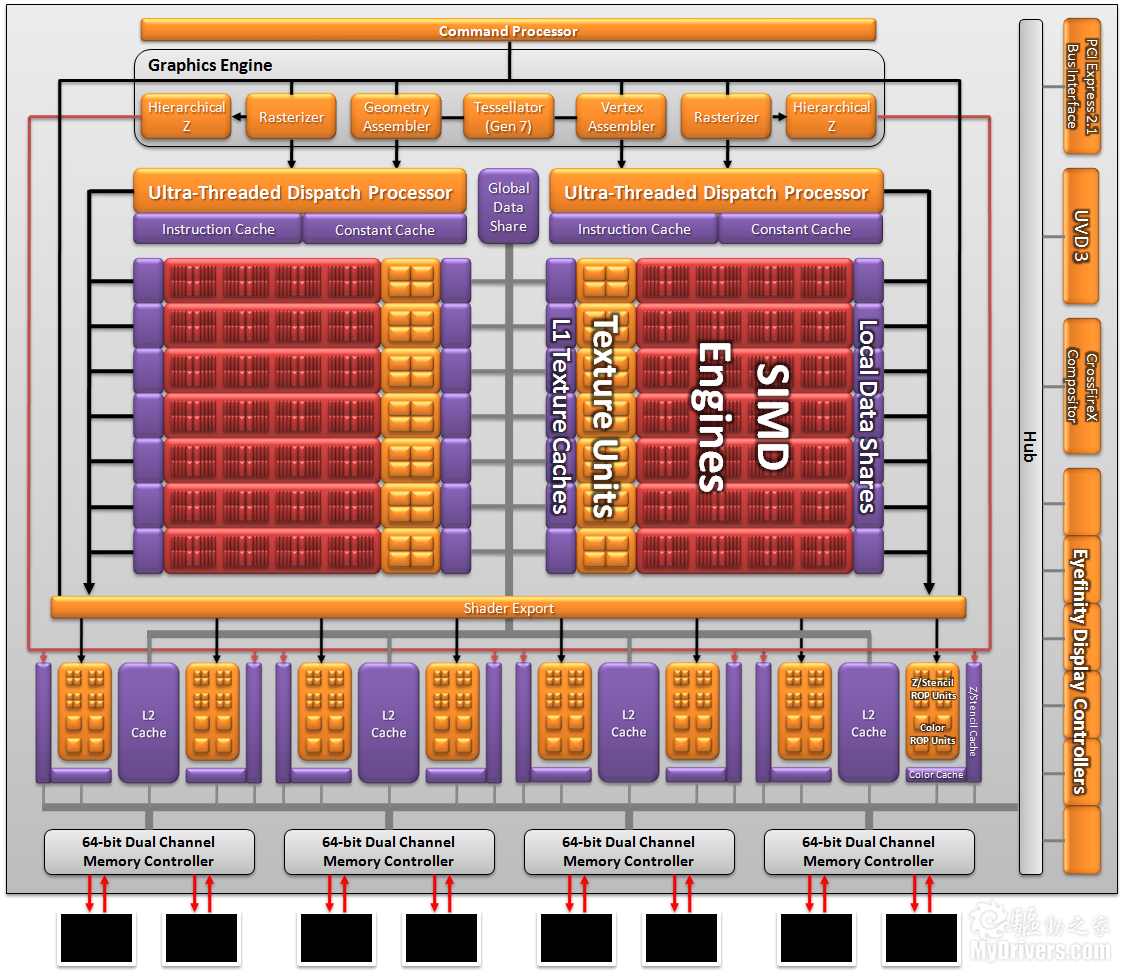 Barts Radeon HD 6800架構圖(Cypress 5800類似) 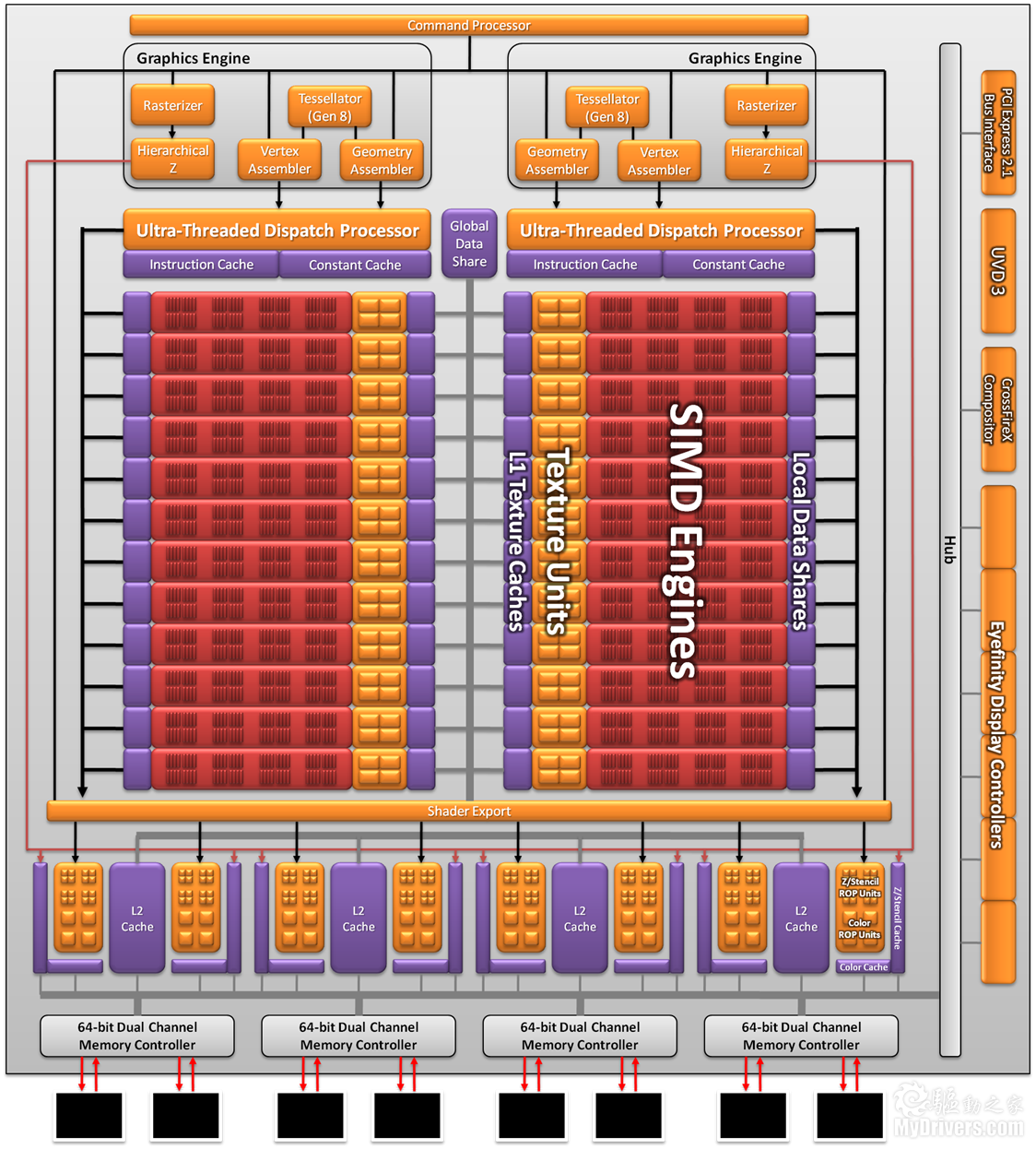 Cayman Radeon HD 6900架構圖 想當年著色技術還是新鮮事物,像素和頂點著色器仍是獨立的。以前ATI為他們的頂點著色器選擇了VILW5設計,因為ATI根據自己的數據得出結論,認為這是頂點著色器區塊的最佳配置,能同時處理一個四分量點積(比如w、x、y、z)和一個標量份量(比如光照)。 2007年,ATI發佈了R600架構的Radeon HD 2000系列,也是自己在PC領域首次引入統一著色架構,而且又一次使用了VLIW5。儘管這是DX10產品,但仍能很好地處理DX9頂點著色。GPGPU通用計算普及之前,這種架構適應得很好。  接下來進入2008年。顯卡廠商在規劃產品的時候一般都要考慮到兩年之後乃至更久的情況,所以Cayman Radeon HD 6900系列的設計那時候就已經著手了。當時GPGPU通用計算才剛剛起步,NVIDIA開始追逐的那個市場最多價值幾百萬美元,DX10遊戲也還沒有成型,但是AMD預測認為,通用計算將在兩年後(也就是現在)變得非常重要,DX9也會基本讓路給DX10/11,所以就必須提前重新評估VLIW5設計的優劣。 果不其然,GPGPU通用計算已經開始大行其道,Windows 7、DX10/11也正在將DX9擠下歷史舞台。根據AMD的內部數據,VLIW5架構的五個處理槽中平均只能用到3.4個,也就是在遊戲裡會有一個半白白浪費了。顯然,DX9下非常理想的VLIW5設計已經過時,它太寬了,必須縮短流處理器單元(SPU),重新設計裡邊的流處理器(SP)佈局。 AMD的顯卡核心架構非常依賴指令級並行運算(ILP),也就是將指令放在單獨一個線程內,和其他可以並行的線程沒有任何關聯。VLIW5下最理想的情況就是五個指令能夠在每個時鐘週期裡、每個SPU上一起調度執行,但這種機率非常低。按說平均使用3.4個已經不錯了,但換算下來還是不足80%,結果就是從工作負載種提取ILP非常困難,導致最好、最壞應用環境相差太多。 與之形成鮮明對比的是線程級並行計算(TLP),那些沒有任何關聯的線程也可以同時執行。這正是NVIDIA在高端核心上所依賴的設計理念,GF100/GF110都是借助TLP達到高效率的標量架構。 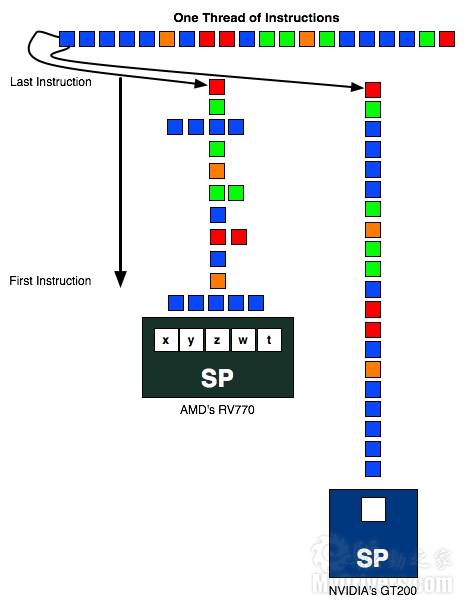 最終,AMD意識到VLIW5架構已經不適合繼續發展,必須針對未來準備一種新的高效率架構,不但要提高平均使用率(大於3.4個),還需要適應並行計算負載,結果就是轉向VLIW4。
__________________
 Which one do you like to choose?
|
|||||||
 2010-12-15, 04:58 PM
#1
2010-12-15, 04:58 PM
#1
|


|
|
Senior Member
加入日期: Mar 2004 您的住址: 長沙
文章: 1,365
|
VLIW4相比於VLIW5最特殊的地方就是去掉了體積最大、可同時處理普通整數/浮點操作和超越操作的第五個SP t單元,或者說特殊功能單元(SFU)。這就意味著,每個SPU可以一次性處理的普通整數/浮點操作數從五個減少到四個,同時還可以將三個SP合併起來處理一個超越操作。
這種變化的好處有很多。並行計算方面最明顯的就是之前用於特殊單元的內核面積可以節省出來安置更多SIMD引擎,比如Cypress Radeon HD 5800 20個,Cayman Radeon HD 6900就增加到了24個,平均下來後者的著色器區塊效率要高10%。在此同時,紋理單元的數量、可以並行執行的線程數量、每個時鐘週期可以執行的64位浮點操作數量都隨之發生了變化,特別是後者使得AMD GPU的64位雙精度運算能力達到了32位單精度浮點的四分之一(以往是五分之一)——事實上單個流處理器單元的計算能力並沒有變化,只不過佈局的重新設計使得彼此工作的效率更高了。  SP變化的同時,暫存器文件卻沒動,於是每個SPU的暫存器所承受的壓力更小了,因為現在只有四個SP爭奪暫存器空間。調度也更簡單了,因為需要調度的SP更少,而且彼此完全相同,不需要考慮w/x/y/z單元和t單元的差別。 遊戲方面的改善也類似。已經習慣了VLIW5架構的遊戲有了更多SIMD引擎可以使用,意味著紋理處理能力更強,計算/紋理的比例也因此降低,有利於那些側重於紋理和過濾而不是計算的遊戲。 當然,任何架構上的變化都會有所犧牲,VLIW4也不例外。對遊戲來說,Radeon HD 6900將不再像以前那麼好地處理VLIW5型的頂點著色器。一般來說這種遊戲都已經很快了,但是如果一開始就受到GPU能力的限制(即顯卡是瓶頸),Radeon HD 6900系列就跑不多快。另一大損失就是當超越操作和矢量操作配對的時候,Radeon HD 6800可以每時鐘週期處理兩個,Radeon HD 6900就需要兩個時鐘週期。AMD認為這種情況很少見,損失也是值得的。 值得一提的是,AMD仍然認為VLIW4是一種風險性的試驗設計,Radeon HD 6900也更像是一個試驗品。此時此刻,AMD應該早已完成了真正的試驗,正在設計採用28nm工藝的後續新核心,是否繼續採用VLIW4也肯定有定論了。 最後,核心架構的變化必然牽涉到驅動程序的轉變與配合。壞消息是,很多針對VLIW5架構設計的著色器編譯器都沒用了,因此初期階段著色器編譯器性能會變差一些。好消息是,隨著時間的過去,AMD會逐漸掌握更好地為VLIW4設計編程,Radeon HD 6900系列也有希望在以後的日子裡獲得性能上的大幅提升(注意只是可能)。 隨著VLIW的縮短,部分代碼重新編寫是必然的了,AMD的著色器編譯器也要經歷一個代碼優化的過程,但如果內核本身就是專為VLIW5而設計的,AMD的編譯器就無能為力了。 順附兩種架構可執行操作的對比: VLIW5: 4 32-bit FP MAD 或者2 64-bit FP MUL/ADD 或者1 64-bit FP MAD 或者4 24-bit Int MUL/ADD 加上1 transcendental或者1 32-bit FP MAD VLIW4: 4 32-bit FP MAD/MUL/ADD 或者2 64-bit FP ADD 或者1 64-bit FP MAD/FMA/MUL 或者4 24-bit INT MAD/MUL/ADD 或者4 32-bit INT ADD/Bitwise 或者1 32-bit MAD/MUL 或者1 64-bit ADD 或者1 transcendental加上1 32-bit FP MAD -- 難怪催化劑10.12版一開始沒支援HD6900,因為那都是屬於VLIW5的啊
__________________
Which one do you like to choose?
|
||
|
2010-12-15, 05:03 PM
#2
|
|
|
Power Member
加入日期: Jan 2004
文章: 573
|
感謝分享!
看起來這個架構以目前的驅動及遊戲還有優化的空間存在 |
|
2010-12-15, 05:20 PM
#3
|
|
|
Power Member
加入日期: Nov 2002
文章: 560
|
說白一點6900就是R600第二囉.....
不過情況比起當時2900XT vs 8800GTX要好太多了...XD 此文章於 2010-12-15 06:31 PM 被 hskao 編輯. |
|
2010-12-15, 06:29 PM
#4
|
|
|
*停權中*
加入日期: Dec 2004
文章: 593
|
好處是隨著驅動優化 4D架構性能會越來越強 但4+1D架構就不會進步了(放棄不理?)希望不要發生
|
|
2010-12-15, 08:53 PM
#5
|
|
|
Golden Member
加入日期: Mar 2003 您的住址: 鳥不生蛋的地方
文章: 2,620
|
引用:
這是必然的吧, 4+1D就會隨著時間凋謝, 畢竟能扎壓的也差不多了. 下一代用28nm因該就有爆炸性增幅吧? (>50%?) |
|
|
2010-12-16, 03:59 AM
#6
|
|
|
Senior Member

加入日期: Apr 2010
文章: 1,048
|
NV也說會有爆炸性增幅
 這次改架構感覺也只是再堆電晶體,被NV給趕過去了 看來NV說的是對的,新架構如果沒有辦法搭配新製程的話進步真的不會很大 跟CPU相反,GPU就是只能告不斷提高製程來增加效能 AMD CPU也要加油阿 |
|
2010-12-16, 04:14 AM
#7
|
|
|
Master Member
  加入日期: Nov 2001 您的住址: 台北市
文章: 2,348
|
相當好的理論文∼
驅動優化之路又要開始了! |
|
2010-12-16, 05:55 PM
#8
|
|
|
*停權中*
加入日期: Jan 2002 您的住址: 台北
文章: 172
|
nVidia 換新架構-> 廢米, nVidia 爛爆
AMD 換新架構 -> 要買要快,driver 可以優化, 鋪平未來之路 |
|
2010-12-16, 08:38 PM
#9
|
|
|
Senior Member
加入日期: Jun 2003
文章: 1,366
|
根本就是盜用Anantech的文章翻譯成中文而已
=.= |
|
2010-12-16, 09:10 PM
#10
|
|





