|
*停權中*
加入日期: Dec 2004
文章: 593
|
目前較合理的推論: (引用)
NVIDIA的硬體架構中,AWS(Asynchronous Warp Scheduler,非同步彎曲調度器)是硬體功能單元,每個SMM單元(類似AMD GCN架構中的Shader Engine渲染引擎)有4個AWS單元。與GCN架構不同,Maxwell 2架構中這個調度器是軟體控制的。 但在AMD的GCN架構中,驅動程式只是負責把佇列發送到ACE(Asynchronous Compute Engine,非同步運算引擎)或者GCP(Graphic Command Processor,圖形命名處理器,也可以處理計算任務)、DMA引擎(複製)中,然後都是ACE引擎負責處理、分配的。 簡單來說就是,NVIDIA的Maxwell架構中佇列、分配等任務都是驅動程式負責的,AWS、DMA引擎、CUDA核心都是硬體實現的,而在GCN架構中,佇列/任務分配/ACE等都是硬體實現的,複製(DMA引擎)也是硬體的,CU單元也是硬體的。 說了這麼多,其實簡單一句話就是NVIDIA的Maxwell 2架構也是支援非同步運算的,但實現這個功能需要軟體及硬體兩方面的參與,而NVIDIA現在出問題的地方就是驅動程式還沒做好支援。 與之不同的是,AMD的GCN架構中非同步運算基本上都是硬體單元實現的,簡化了開發,也不依賴驅動程式。 |
|||||||
 2015-09-06, 10:15 PM
#71
2015-09-06, 10:15 PM
#71
|


|
|
Power Member
 加入日期: Jun 2012
文章: 673
|
Tech Report’s David Kanter said in a video podcast that people who work at Oculus have mentioned how preemption context switching, a very important feature especially in VR scenarios, can be really bad on NVIDIA cards.
引用:
Read more: http://wccftech.com/preemption-cont.../#ixzz3kyCRKAtk 得益於Asynchronous shading,Oculus(做VR虛擬實境的)員工認為,在content switch優先權切換上,最好的是AMD,再來是Intel,Nvidia次之。 NVIDIA Will Fully Implement Async Compute Via Driver Support http://www.guru3d.com/news-story/nv...er-support.html nVDA現在看來要用Driver去補足,就要看後續如何,或是等待Pascal了... |
|||
|
2015-09-06, 10:50 PM
#72
|
|
|
*停權中*
加入日期: Jun 2015 您的住址: 金一十大女支三
文章: 1,282
|
把這件事換個口語化說法讓一些沒辦法follow全球主要英文論壇的朋友參考參考
處理器談的就是效率 評量一個處理器 就是看各種運算下理論值與實測值 不管是GPU還是其他各種不同目的之處理器 設計目標一定是針對該問題提供最適解 當你把工作區分更細 對於管線深化的處理器一定具有加分作用(RISC思維) GCN跟Streamroller剛好是這類型 為什麼Intel要主導CPU之"指令集" 關鍵就是誰搶到指令集趨勢於製造硬體上更有優勢 GPU就是一種針對3D/2D影像的"Specialized Processor" 所以不會也不該拿不屬於其應用範圍之用途來評量 DirectX 12一定是一個不屬於NV應用範圍的產物 所以可以跑 但是沒有"specialize"不要緊  效率降低是因為AMD使用行銷戰術讓GPU Architecture有如變形金剛 想想之前兩家公司怎麼告訴你的吧 DX12有多階層 而且舊世代GPU可支援 注意一下 支援=可使用 特化=高效率(這樣形容很粗糙 但是可接受) XBOX one PS4是不是跟PC架構很接近?另外一個很好的例子是Emulator 模擬器 DX12能否在之前推出的產品跑?兩方陣營的舊GPU架構都支援 DSR與VSR能不能再之前的產品跑?你會不會在舊卡上面開DSR(VSR) 4K解析度 就如同GTX 970 最後的0.5GB 可以用但效率不彰 不要緊  如果這種問題都可以用驅動修的好 那我們就會有另一家外星科技公司出現 Intel的架構喔 呵呵呵 自己參考 http://www.anandtech.com/show/9483/...th-generation/4 一直以來x86受限舊包袱 很難走入新世界 平行運算就是其中一例 -------- 對於追求效能頂端的消費者 DX12還有點遠 而且還有金手指 Unreal Engine 4似乎沒用到這些功能 DX12要普及仍須相當一段時間 現階段買顯示卡考慮DX11比較實在 沒特化又不是罪 還要凹到有 真是夠了 而且都是軟體的出來解釋  此文章於 2015-09-07 12:01 AM 被 lzarconlony1 編輯. |
|
2015-09-07, 12:00 AM
#73
|
|
|
Master Member
  加入日期: Nov 2010
文章: 2,414
|
引用:
其實我還是不明白為何PCWATCH說NV的硬體架構是SOA 你卻說是AOS...
__________________
新。弱弱的戰績  
|
|
|
2015-09-07, 12:18 AM
#74
|
|
|
Master Member
加入日期: Sep 2003
文章: 1,810
|
關於 context switch 也有找到一篇文章,應該可以補充之前提到粒度大小的東西
http://pc.watch.impress.co.jp/docs/...926_668620.html 重點在段落標題"CPUライクな柔軟なコンテクストスイッチ"、"インドでTongaの詳細を発表" 這兩段 簡單的翻譯是一般GPU使用的context 大(也就是之前提到的粒度大),記憶體儲存有延遲性 以前的GPU是全體跑一個context,要做context switch 就要把沒處理完的context先儲存起來 這時候會有延遲性大的問題 AMD 為了要以CU為單位去跑 context 需要降低其延遲性,所以context就被切成八份(也就是粒度小) 這樣需要context switch時 可以單獨切換其中一個,而不必一次切換掉八個; 不過AMD說能作到像CPU那樣的context switch是tonga(GCN1.2)之後才有辦法 GCN1.0、GCN1.1 還沒辦法,所以Kaveri(GCN1.1)沒有相容HSA 1.0,到carrizo才有相容hsa 1.0 文章裡面也寫到NV的Maxwell 有很像context switch 構造的東西,但NV還沒把它有效化 或許NV之後可以用軟體方式修正 只不過kaveri 其實也有 context switch 構造,AMD最終是對硬體進行修正產生了GCN1.2才支援context switch context switch 或許可能是個重點 但GCN1.0、GCN1.1(不能switch) 如果也能受惠DX12 那就回到基本的問題上可能跟粒度大小有直接關係 此文章於 2015-09-07 01:22 PM 被 orakim 編輯. |
|
2015-09-07, 01:17 PM
#75
|
|
|
Master Member
加入日期: Sep 2003
文章: 1,810
|
[youtube]v3dUhep0rBs[/youtube]
之前AMD 有弄了一個影片解釋asynchronous shaders 第一個片段是在解釋傳統的方式,粒度大只能一串一串的跑 第二個片段是在解釋preemption,雖然還是一串一串的 但是可以暫停context 插入其他context 運算完再回復原來的context (有點類似context switch) 第三個片段是AMD採用的asynchronous shaders 粒度小排程運算,影片中沒有顯示context switch 的功能 此文章於 2015-09-07 01:56 PM 被 orakim 編輯. |
|
2015-09-07, 01:53 PM
#76
|
|
|
Advance Member
加入日期: Jan 2002
文章: 449
|
Microsoft一直想做到的是mid-buffer preemption,目前nVidia的GPU在這方面確實有所限制,也在和DX team討論其他的可行方式,因其最終目的是在降低latency。不過最近這個benchmark的議題主因可能倒不是在此,而是遊戲針對AMD GPU的特性使用async compute的方式,導致speedup的因素來自於compute-compute concurrency而非compute-render concurrency。
引用:
|
|
|
2015-09-07, 02:30 PM
#77
|
|
|
*停權中*
加入日期: Jun 2015 您的住址: 金一十大女支三
文章: 1,282
|
引用:
你一直在這邊中傷 有本事回overclock.net那帖去講這些 好嗎 看看那些人有沒有鬼島人這麼好說話 甚麼是針對AMD? Async Compute甚麼時候還有分不同廠商 現在就是因為DX12做法跟以前不同 GCN得益較多 很簡單的事實有需要扯出對手中傷論嗎  源點是第三方 這樣也能解讀成對手出招? http://wccftech.com/nvidia-async-co...12-oxide-games/ threads切小deep pipeline受益較多本來就很合理 asynchronous shaders影片也只是圖解這個概念 GCN如果是一群螞蟻 那NV就是十六隻蝗蟲(GM204) DX11時螞蟻無法團結 工作分配不到極限 打不贏蝗蟲 DX12把工作切細 螞蟻能發揮效率 蝗蟲習慣單打獨鬥 要面對平行運算效率下降 螞蟻甚麼工作都接 蝗蟲身價太高沒等上面發號司令就不幹  驅動真能把Warp Scheduling變的不同? 通常硬體實做才是能真正發揮效率關鍵 ------ SMX, Kepler  SMM, Maxwell  不管怎麼說 這樣改進還是脫離不了原先概念 CUDA 32個一組或許在DX11很吃香 DX12 1+31能夠Work嗎? ------ Shader Processors與Unified Shaders 兩個名詞的迥異其實道明設計方針的差異性 Maxwell, GM204 2048 Shader Processors 128 Texture mapping units 64 Render output units  GCN 1.2, Tanga Pro 1792 Unified Shaders 112 Texture Mapping Units 32 Render Output Units  題外話 似乎看到有人在做這兩者的效率分析囉 比較令人納悶的是好像是AMD的人 這什碼情況 有點後悔今年買GTX 980...應該再等等  |
|
|
2015-09-08, 09:26 AM
#78
|
|
|
*停權中*
加入日期: Dec 2004
文章: 593
|
簡單來說就是全硬體執行與半硬體+軟體上處理速度上的差別 NV桌面市佔較高是沒錯(但還是排老二),但新一代家用遊戲機AMD的份額更高(可視為100%),我還是強調在DX12 AMD獲得優勢是必然的,畢竟是AMD先提出改善效率的方法(以自家GPU先去實做並獲得微軟的認同後放在DX12內)
|
|
2015-09-08, 09:55 AM
#79
|
|
|
*停權中*
加入日期: Jun 2015 您的住址: 金一十大女支三
文章: 1,282
|
引用:
你一直在這邊中傷 有本事回overclock.net那帖去講這些 好嗎? 看看那些人有沒有鬼島人這麼好說話 針對AMD??? Async Compute甚麼時候還有分不同廠商 假設N公司賣水 A公司也賣水 難不成N公司的H2O是外星結構跟A公司有所不同? 頂多就是萃取水 包裝水的方法不同 "本質"必然相同 Async Compute就是一種"本質"而已 現在就是因為DX12做法跟以前不同 GCN得益較多 很簡單的事實有需要扯出對手中傷論嗎 源點是第三方 這樣也能解讀成對手出招? http://wccftech.com/nvidia-async-co...12-oxide-games/ threads切小deep pipeline受益較多本來就很合理 asynchronous shaders影片也只是圖解這個概念 引用:
驅動真能把Warp Scheduling變的不同? 通常硬體實做才是能真正發揮效率關鍵 ------------ SMX, Kepler 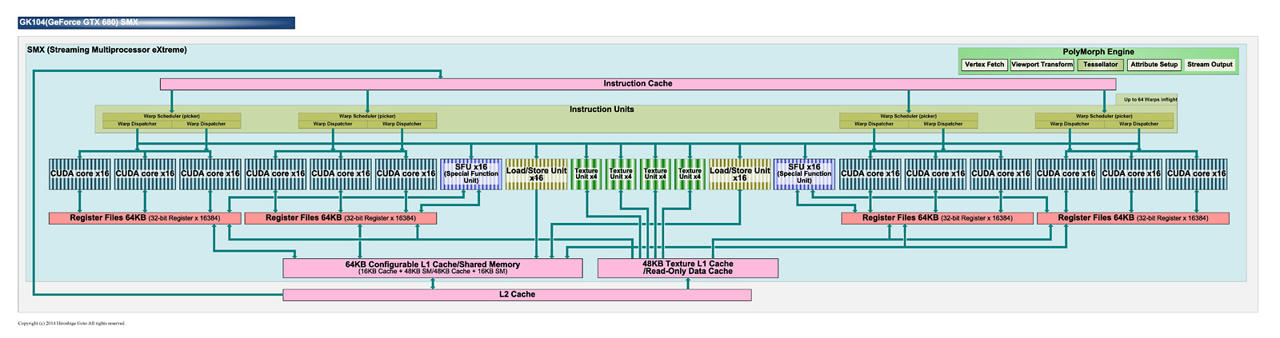 SMM, Maxwell 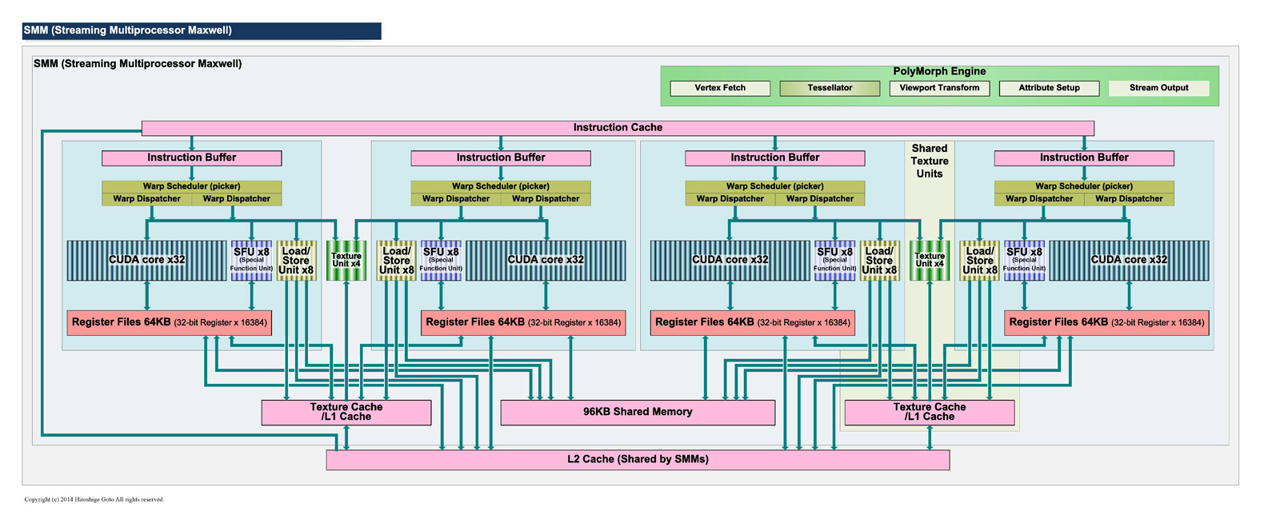 不管怎麼說 這樣改進還是脫離不了原先概念 CUDA 32個一組或許在DX11很吃香 DX12 1+31能夠Work嗎? 跑的快嗎?會比兩隻老虎還要快嗎 ------------ Shader Processors與Unified Shaders 兩個名詞的迥異其實道明設計方針的差異性 Maxwell, GM204 2048 Shader Processors 128 Texture mapping units 64 Render output units 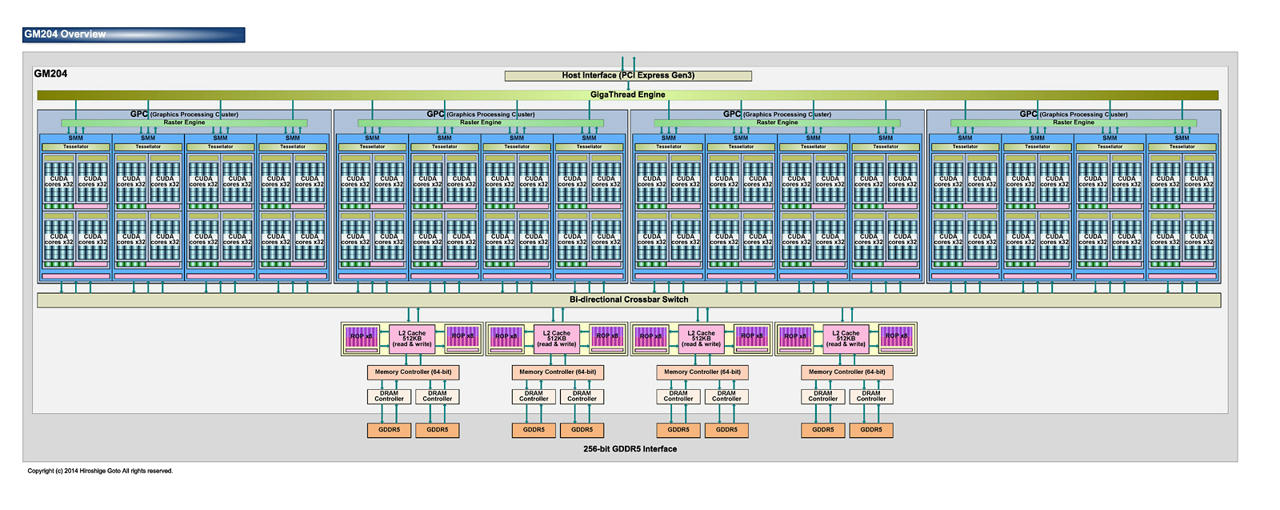 GCN 1.2, Tanga Pro 1792 Unified Shaders 112 Texture Mapping Units 32 Render Output Units 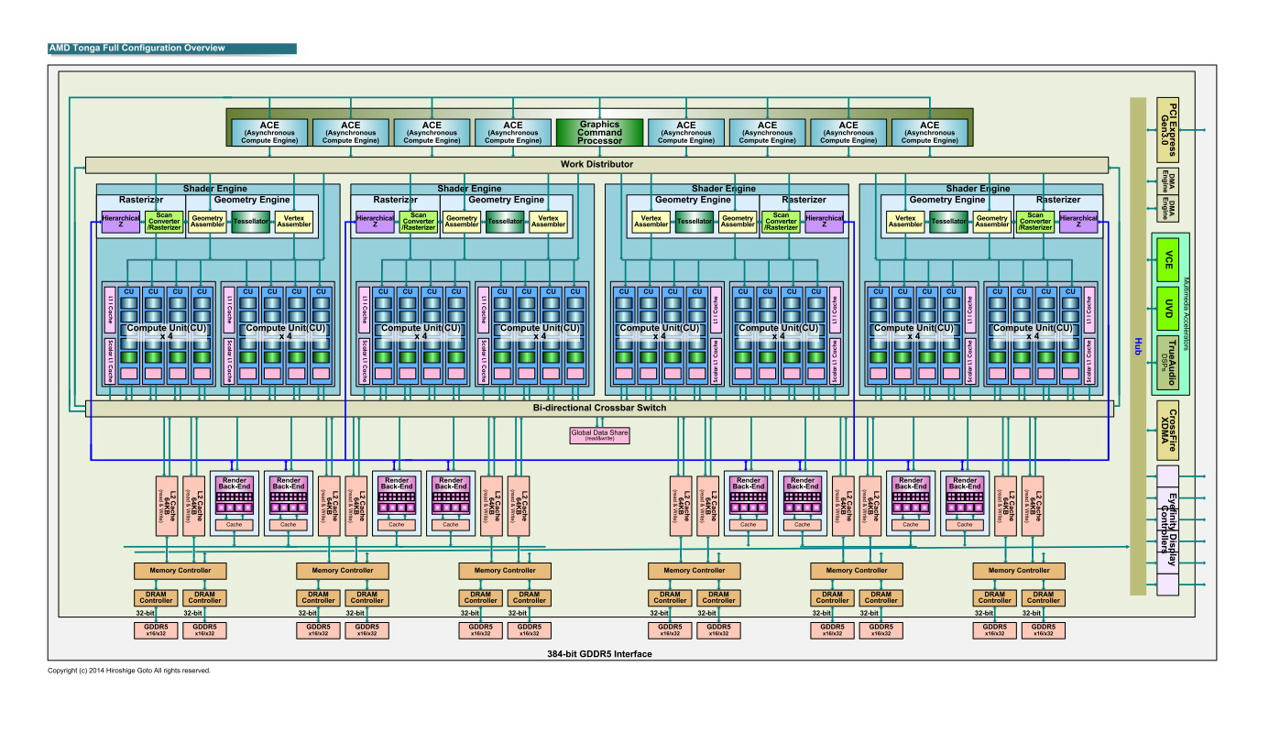 題外話 似乎看到有人在做這兩者的效率分析囉 比較令人納悶的是好像是AMD的人 這什碼情況  有點後悔今年買GTX 980...應該再等等 此文章於 2015-09-08 10:34 AM 被 lzarconlony1 編輯. |
||
|
2015-09-08, 10:30 AM
#80
|
|





