|
Major Member
 加入日期: Dec 2004
文章: 131
|
引用:
你忘了 把 Clock Speed 加回去 也就是 664*1.25 = 830 830 / 600 = 1.383 也就是 4.2GHz 的BD會比 3.3 GHz X1100 快 38% 你數學真的不好阿  放心~我也沒好到哪裡去 我的算法瑕疵很大的∼因為我沒有估算模組與模組溝通的Overhead 所以現實上~ 假設 X1100 = 600 , BD 一個模組 = 160 4個模組 會是 160*4*overhead (基本上看軟體最佳化程度) 所以一定小於 640 不果整體的概念基本上是正確的 還有那個測試....真的不要凹了 除非是故意的(當然現在看回去非常有可能) 請問你不同處理器Benchmark 只靠比例怎麼比較 ? 沒有base怎麼比? 所以就算是3個測試∼ 他也是數據化之後加總 所以X1100 三個測試跑得分是100分的話 BD 就會是 150 分 這樣計分準不準確~~當然不準確~~但是有沒有算錯?沒有 我可以同意這種計分方式完全無意義,但很遺憾∼該網站沒有說錯 是50% 如同我之前幾篇回的 BD的架構上沒有問題,事實上我認為接下來Intel 一定會跟近 但事實上很糟糕是事實 模組化的好處是什麼?除了可以Die size的優點以外 最大的好處就是在多執行緒的環境底下,模組中的執行緒可以很快的相互切換資源 這也是為什麼Bulldozer 如此糟糕 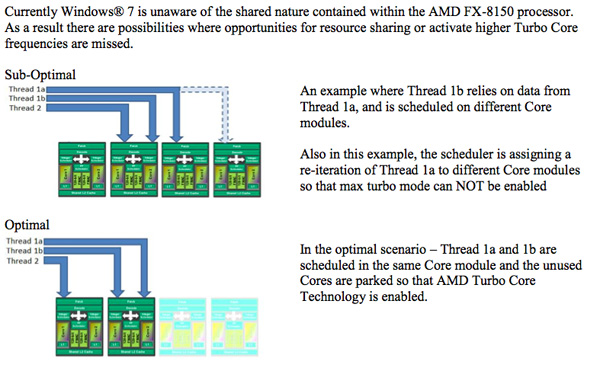 在目前Window7的情況 會製造出許多 BD 效的的 Worst case 1. A thread1 跟 A thread2 會被擺在不同模組 2. (Maybe) Race condition with Shared FP unit 3. Pipeline impact (cache miss, Branch prediction fail 這也就是為什麼 同樣四個執行緒 4M/4C 表現最好 4M/8C 次之 2M/4C 最糟 |
||||||||
 2011-10-28, 05:36 PM
#41
2011-10-28, 05:36 PM
#41
|


|
|
Major Member
加入日期: Dec 2004
文章: 131
|
引用:
引用:
我決定特別Highline 這段紀念一下閣下的數學能力以及閱讀能力 |
||||
|
2011-10-28, 05:58 PM
#42
|
|
|
Master Member
  加入日期: Sep 2003
文章: 1,810
|
引用:
你不看我的文就算了 連你自己的文都搞不清楚,你自己的文寫的是同時脈 也就代表我引用你的文當然也是在講同時脈 至於你時脈要加的多誇張是你的事 別把我扯進去 高興的話 拿Pentium 初代來時脈加到無比恨天高的程度 說他比i7快 這也是你的事與我無關 引用:
但這個測試不會代表著BD快過i7 150% yes,那篇芭樂文指的i7 950 是而不是你提的K10 (連自己的引用來源都看錯 你也太厲害了吧) 多個測試直接加總起來 數字上是可觀但是不公平 高興拿i5、i7跑個幾千上萬測試 說i7總和分數比i5高幾百倍,不代表i7真的比i5快幾百倍 AMD都放新聞稿出來說是不公平的測試 明顯的誤解測試,你別再凹了吧 引用:
事實上也沒人可以證明他錯 AMD沒有把它測試的環境 軟體 參數放出來,沒人可以複驗 而且這裡沒人說他錯吧,誤解跟錯是兩回事 你把它弄在一起是要幹嘛 我說的是"誤解",三個不同測試累加在一起是一個很大的問題 這就是誤解 懂嗎 好吧 既然這麼看不開,那麼舉例吧 A欠B NT$100,A欠C $100 不能代表A總共欠了100x2=200 ,而是NT$100+$100 光不同測試要怎麼統一單位、要用多少計算加成就是很大的問題 就算不進行加成處理、單位也用比例來normalize來處理 還有個累加的測試的問題 假設一個相同的測試A比B快10%,同樣測試測了三次之後會變成A比B快了30%嗎? 誤解誤很大是事實,有沒有錯我不知道 AMD又沒有公布測試設定環境 明明自己搞不清楚這個測試哪裡有問題就說嘛,還要人過來打你的臉啊? 引用:
然後? 你到底要說的是什麼 重複大家都知道的東西是在幹嘛? 迴避"你認為推土機會比K10(實際上圖片寫的是i7 950)快150%" 還是迴避"你被指出錯誤卻從不認錯"的部份 還是迴避"你認為4M/8C的單執行緒效能應該跟2M/4C一樣" -- 站出來面對吧,錯不可恥啊 你說你沒錯 被指正後甚至還說沒人指正你的錯誤 這太離譜了吧 如果是在反串,拜託你也串好看點吧 串到我認為"回你的文是在浪費時間"是怎麼樣? 拜託真的拜託,串好看點吧 此文章於 2011-10-28 06:29 PM 被 orakim 編輯. |
||||
|
2011-10-28, 06:20 PM
#43
|
|
|
Major Member
加入日期: Dec 2004
文章: 131
|
引用:
引用:
繼續繼續~我開始覺得有趣了 |
||
|
2011-10-28, 06:34 PM
#44
|
|
|
Master Member
加入日期: Sep 2003
文章: 1,810
|
你就自high吧
話說25%時脈提升是什麼東西 我還從來沒看過咧(至少AMD沒這樣講過) 一個自high人的數據 一個誤解新聞 甚至還看錯cpu的自high人捏造數據 XD -- 真是浪費時間 此文章於 2011-10-28 06:49 PM 被 orakim 編輯. |
|
2011-10-28, 06:43 PM
#45
|
|
|
Major Member
加入日期: Dec 2004
文章: 131
|
引用:
http://www.anandtech.com/show/3865/...ntations-online 我的基本設定完全參考官方slide 就跟你說了,你那串動東西當時是新聞 現在早就是沒用的資訊了 80%CMP 效能 要達到同效能時脈是不是差 1.25 奇怪勒,小學數學都不會算 到底是浪費誰的時間啊  |
|
|
2011-10-28, 09:29 PM
#46
|
|
|
Master Member
加入日期: Sep 2003
文章: 1,810
|
說真的
你就自high吧,沒人可以管你 -- 被指正到這種程度,還無視 還沒看過這種人 |
|
2011-10-28, 09:58 PM
#47
|
|
|
Major Member
加入日期: Dec 2004
文章: 131
|
引用:
有本事 拿出你的算法証明我錯 要不然出張嘴我也會啊 不是我不想認同你 而是你對於推土機的認知有問題 就現實的8150fx來說,的確只有在第二階turbo才能達到4.2GHz 但是 8170fx 第一階就能達成 而且是all 8 Cores 所以現有的fx8150模擬4.2GHz 的確不會是一般的case 更不用說目前模組 只有 CMP 60%-70% 但不代表我所計算的效能超出推土機的規格 更應該是說 這是期待中推土機應有的效能 |
|
|
2011-10-28, 10:43 PM
#48
|
|
|
Master Member
加入日期: Sep 2003
文章: 1,810
|
引用:
算法? 現在要扯到算法? 拜託 你之前錯的地方沒承認 還要扯算法 XD 誰有時間跟你這樣玩下去 -- 就跟你說 你要自high沒人會管 但請不要扯到我身上 此文章於 2011-10-28 10:56 PM 被 orakim 編輯. |
|
|
2011-10-28, 10:53 PM
#49
|
|
|
Major Member
加入日期: Dec 2004
文章: 131
|
引用:
錯錯錯~~~~錯在哪? 你的一開始的回應 引用:
結果是誰錯? 誰沒講到 L2 ? 引用:
是誰錯? 誰沒想到推土模組? 引用:
是誰錯? 誰不會算數? 新台幣一百元+美金一百元 = 100 點購買力 這樣很難嗎? 擺明就沒算錯~凹什麼?會有 30%+45%+45% 這算法嗎? 你的30%是跟誰比? 算出30%? 莫名其妙 引用:
你對在哪? 引用:
是誰錯?誰的時脈高?會是X1100嗎? 還是推土機要降頻跑你才覺得公平? 引用:
是誰錯? 難道你貼的新聞鏈結是同樣的Bench測三次嗎?他上面明明寫 media rending game 你還想要怎麼凹 AMD slide 要怎麼加權去算隨他高興啊? slide 上面明明白白就是寫 i950 是 1 BD 是 1.5X 搞不懂的人到底是誰啊 爭論這個無意義的東西要多久?我都還沒把你亂寫BD 整數執行倒退十年的事情拿出來鞭你 要不要順便解釋一下~退十年怎麼來的? 引用:
這本來就因該要一樣~~~你到底有懂不懂Computer Architecture ? 會不一樣快在哪裡? 更甚至就算是四個執行緒~4M/4C 跟2M/4C 的效能理當接近 唯一例外就是該Task絕大多數是 FP Unit 運算~ 這樣 4M才會有優勢 很難懂嗎?全世界哪來這麼先進的模組架構~關掉一個整數運算單元~另一個整數運算 單元效能就會成長的?他是模組耶~FP+2INT Share前面好個stage的pipeline stage 會不一樣快架構上就不可能,還敢說我out of spec 拜託~是誰不懂? 麻煩你行行好~水準再這樣~ 就請不要回我的文好不好 你根本就搞不清楚 模組 跟 CMP 的差異 此文章於 2011-10-29 12:08 AM 被 kqalea 編輯. |
||||||||
|
2011-10-29, 12:05 AM
#50
|
|





