|
Master Member
  加入日期: Sep 2003
文章: 1,810
|
> 再說Kaveri沒了HSA實在想不出有什麼賣點
> AMD,我真是搞不懂你啊  很簡單因為HSA需要OS 跟軟體的支援; 沒有這兩個東西只有硬體也等於沒有HSA 現在兩個都沒有 ,有沒有GPU差異性不大(反正都沒HSA) PS.這個沒軟體可用的狀況恐怕會持續一年左右(個人猜測) > 有 HSA 一樣沒賣點啊,我覺得 HSA 在科學運算領域才比較有發揮空間 > GPU 相較於 CPU 的優勢在於 GPU 有相當大量的運算單元 > 所以必須丟可以高度平行化的工作給 GPU 計算,這時 GPU 的優勢才會展現出來 你講的這部分是過去GPU運算的方式,但HSA跟他有根本上的不同 以程式來說運算方式可以分成可平行化 跟不可平行化 過去使用GPU的運算可以說是完全平行化,CPU沒有介入實質運算 即便CPU介入也因為延遲過高 頻寬過低 整體效能差,跟純CPU運算沒有太大差異(或者更慢) 所以看不到CPU+GPU這種應用方式 完全平行化的運算方式,在一般使用者環境很少見; 實際上不可平行化的運算佔了不少部分 (但還是有可平行化運算的部份存在) HSA設計的目標是可平行化給GPU 不可平行化給CPU 讓CPU GPU各自負責他們適合的工作,徹底解決運算上的瓶頸 這在電腦史上很明顯是一場前所未見的大革命 (上一次革命很巧也是AMD掀起的:AMD64) 能不能成功就看AMD能熬多久,軟體是需要時間去堆出來的 > AMD從一開始就不該推兩個平台 y > 資金、人力與對手的差距懸殊 不過你後面的發言似乎以socket區別平台 而我認為的兩個平台是bulldozer,bobcat 這兩個架構出發點相同,只是實現方式略微不同;就最終結果而言 兩個執行效率非常接近 實在沒必要為此開發兩種架構 > 主機板的供電模組那就過不了關 > 架構、製程沒翻新進步 > APU很難達到R7-260的水準 其實你忘了一件事,DDR3記憶體頻寬太小; 即便塞個R7-260那樣大的GPU進去,發揮出來的效能跟A10 7850K 也不會有太大差異 也只有像PS4那樣系統記憶體採GDDR5 才能發揮GPU的極限 或者你可以反過來想,AMD就是因為記憶體頻寬問題才設計那樣的GPU 此文章於 2014-08-25 09:59 AM 被 orakim 編輯. |
|||||||
 2014-08-25, 09:54 AM
#31
2014-08-25, 09:54 AM
#31
|


|
|
Golden Member
 加入日期: Dec 2001
文章: 2,930
|
HSA弄得起來Intel就會弄個很像的東西出來
 感覺AMD很像Intel的實驗室 3DNow!->SSE Cool'n'Quiet->SpeedStep拿到桌上型CPU K8 CPU內建記憶體控制器->Intel Nehalem架構 HyperTransport->QuickPath AMD64->Intel64(就是有小地方跟你不相容) Phenom共用L3架構->Nehalem架構跟之後的Core SSE5->AVX APU->CPU內建顯示 此文章於 2014-08-25 10:25 AM 被 bureia 編輯. |
||
|
2014-08-25, 10:16 AM
#32
|
|
|
*停權中*
加入日期: Apr 2014 您的住址: 四季如夏的地方
文章: 1,796
|
引用:
AMD去探索另外一條路, 然後Intel再用資源壓過去...  |
|
|
2014-08-25, 10:28 AM
#33
|
|
|
Master Member
加入日期: Sep 2003
文章: 1,810
|
NintendoFamicom的發言讓我想到一件事
如果是以HSA為前提的狀態下,GPU的compute unit 要幾個才划算 (因為HSA運算有極限 到一定程度 效能增加很慢) 假設一個 compute unit下,GPU的效能是CPU的三倍 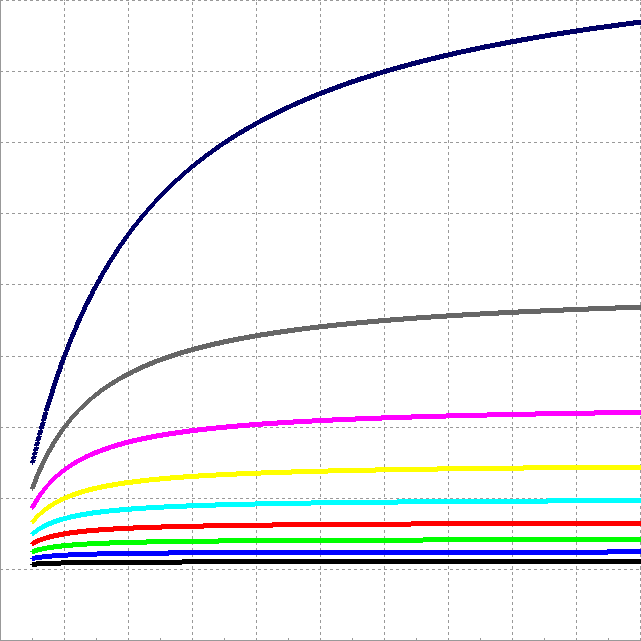 橫軸是GPU的compute unit(間隔2),縱軸是效能(間隔1) 顏色是可平行化程度(間隔10%)_80%(灰色) 70%(紅紫) 60%(黃) 如果只要求HSA程式 跟intel 純CPU 差不多快, 以可平行化40%(紅)來說 1個CPU 配上2個cu(4個CPU就要8個cu) <-這比例剛好就是A10-7850K 如果講求划算的話,以可平行化50%(螢光藍)來說 大概CPU:GPU=1:4 很明顯A10-7850K GPU的cu 少了一半 如果要補滿這一半 換成AMD的說法應該就是20核心的APU (CPU:GPU=4:16) 此文章於 2014-08-25 11:55 AM 被 orakim 編輯. |
|
2014-08-25, 11:53 AM
#34
|
|
|
Junior Member
加入日期: Jun 2012
文章: 733
|
引用:
這樣的話,AMD 的處境就更加艱難了,因為程式不但要整個重寫,而且重寫難度大增,因為還要分別切割工作給 CPU 和 GPU 再說現在的 CPU 也足以應付一般應用了,工程師恐怕也不願意為了支援 HSA 重寫 Code.. 想再請教一個問題,那就是 CUDA 6 支援統一尋址,也就是說 GPU 和 CPU 應該會共用 CPU Memory (Main Memory) 但 CPU 會同意讓 GPU 動它主管的 CPU Memory 嗎?CUDA 6 的統一尋址到底是怎麼辦到的啊?  此文章於 2014-08-25 12:03 PM 被 Jiun Yu 編輯. |
|
|
2014-08-25, 11:59 AM
#35
|
|
|
*停權中*
加入日期: Jun 2014
文章: 286
|
要推HSA
我認為最最重要的是AMD要拿出一個革命殺手級的應用軟體 像是轉檔 AMD若能找到廠商合作,給予軟體開發支援 能讓A10-7850K的HSA轉檔 時間縮到i7 QSV的一半 畫質是純CPU運算的水準 這樣其他轉檔軟體未來就會不得不推出支援HSA的版本 重點在於第一個齒輪要怎麼去推動它...... 此文章於 2014-08-25 01:09 PM 被 NintendoFamicom 編輯. |
|
2014-08-25, 01:08 PM
#36
|
|
|
Master Member
加入日期: Jul 2002
文章: 1,766
|
引用:
不知跟boinc之類的科學運算結合有沒有搞頭 或是某些像PCB LAYOUT之類需要強大計算力的 (比特幣?)
__________________
Ark-Baroque-Yield-Sacrifice-StarDust Elis的肖像,少年Abyss尋找的女孩 為愛打開冥府大門,揭開無限輪迴的少女 "那個女孩,是我尋找的Elis嗎?"假面男如此說著 最後認清真相的少女EL,夢想與現實的交會點 第四地平線,那個樂園的名字是"ELYSION"或是"ABYSS" ===================== Dropbox推廣連結 http://db.tt/ZD1hTLkG |
|
|
2014-08-25, 07:21 PM
#37
|
|
|
Regular Member
 加入日期: Jun 2012
文章: 71
|
越來越深奧了.....看不懂...
 |
|
2014-08-25, 10:38 PM
#38
|
|
|
Master Member
加入日期: Sep 2003
文章: 1,810
|
> 再說現在的 CPU 也足以應付一般應用了,工程師恐怕也不願意為了支援 HSA 重寫 Code..
有多的效能出現就可以有更多應用方式出現 而且效能需求從來沒少過,現在不重寫code 未來也要重寫 另外HSA也不只限制在x86上,ARM也有(AMD預計明年會推的skybridge framework) > 但 CPU 會同意讓 GPU 動它主管的 CPU Memory 嗎?CUDA 6 的統一尋址到底是怎麼辦到的啊? 傳統是不會同意(安全性問題) CPU能處理的權限跟GPU不同 資料頂多只能單方向傳輸 CUDA透過更換CPU函式庫的方式,讓權限不同的安全性問題得到解決 透過軟體方式 將以往cuda要人工處理的部分讓它可以自動執行 省掉麻煩 而AMD方面之前有寫過(在下面這邊) http://www.pcdvd.com.tw/showthread.php?t=1028634 另外今年一月AMD有提到一件事, 他不只要在記憶體實現這種技術 未來連cache也要做到這種雙向溝通 目前的kaveri 在cache方面還是只有單向傳輸(只有GPU 才可以從CPU cache拿資料) AMD是說因為cache 雙向溝通的技術過於複雜會拖到kaveri的上市,所以放棄了但未來還是會有 > 我認為最最重要的是AMD要拿出一個革命殺手級的應用軟體 > 像是轉檔 這是一定的,AMD ppt裡提到一個HSA廠商 就是在弄x265 可惜x265目前發展中 畫質還比不上很成熟的x264 假設x265達到理想的畫質 有試過x265的應該知道他真的很慢, 不會有人想用純CPU來跑4K video的x265編碼,一定會採取某種加速的方式 此文章於 2014-08-26 12:34 AM 被 orakim 編輯. |
|
2014-08-26, 12:27 AM
#39
|
|
|
Junior Member
加入日期: Jun 2012
文章: 733
|
引用:
剛看了一下 Unified Memory in CUDA 6,資料似乎還是必須在 GPU 與 CPU 之間搬來搬去,只是之前必須手動搬移,現在有了 managed memory,系統會自動幫你搬 感覺有點像是"表面上的統一記憶體 (Unified Memory)",只能用來減輕程式開發者的負擔以及讓程式碼不再那麼冗贅 (不會再有一堆 cudaMemcpyXXXXToXXXX() 了) CUDA 以後有可能做到直接操作 CPU Memory,不用再把資料搬到 GPU Memory 嗎? 我在想即便可以,但 GPU 離 CPU Memory 那麼遠,這樣運算速度真的快得起來嗎?如果真的快不起來,那 CUDA 是不是前景堪慮了啊 (相較於 AMD 的 HSA) 此文章於 2014-08-26 09:08 AM 被 Jiun Yu 編輯. |
|
|
2014-08-26, 09:04 AM
#40
|
|





