引用:
|
作者freaky
Microsoft一直想做到的是mid-buffer preemption,目前nVidia的GPU在這方面確實有所限制,也在和DX team討論其他的可行方式,因其最終目的是在降低latency。不過最近這個benchmark的議題主因可能倒不是在此,而是遊戲針對AMD GPU的特性使用async compute的方式,導致speedup的因素來自於compute-compute concurrency而非compute-render concurrency。
|
你一直在這邊中傷 有本事回overclock.net那帖去講這些 好嗎?
看看那些人有沒有鬼島人這麼好說話 針對AMD???
Async Compute甚麼時候還有分不同廠商
假設N公司賣水 A公司也賣水 難不成N公司的H2O是外星結構跟A公司有所不同?
頂多就是萃取水 包裝水的方法不同 "本質"必然相同 Async Compute就是一種"本質"而已
現在就是因為DX12做法跟以前不同 GCN得益較多
很簡單的事實有需要扯出對手中傷論嗎
源點是第三方 這樣也能解讀成對手出招?
http://wccftech.com/nvidia-async-co...12-oxide-games/
threads切小deep pipeline受益較多本來就很合理
asynchronous shaders影片也只是圖解這個概念
驅動真能把Warp Scheduling變的不同?
通常硬體實做才是能真正發揮效率關鍵
------------
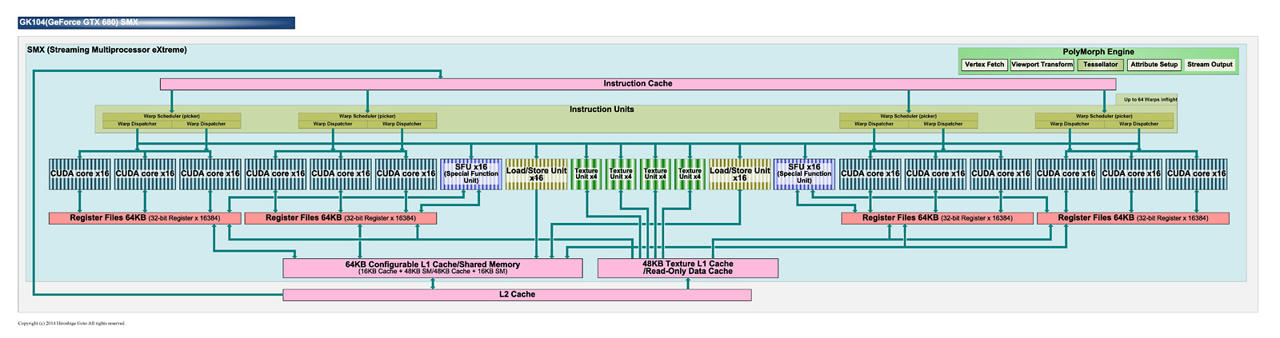
SMX, Kepler
SMM, Maxwell
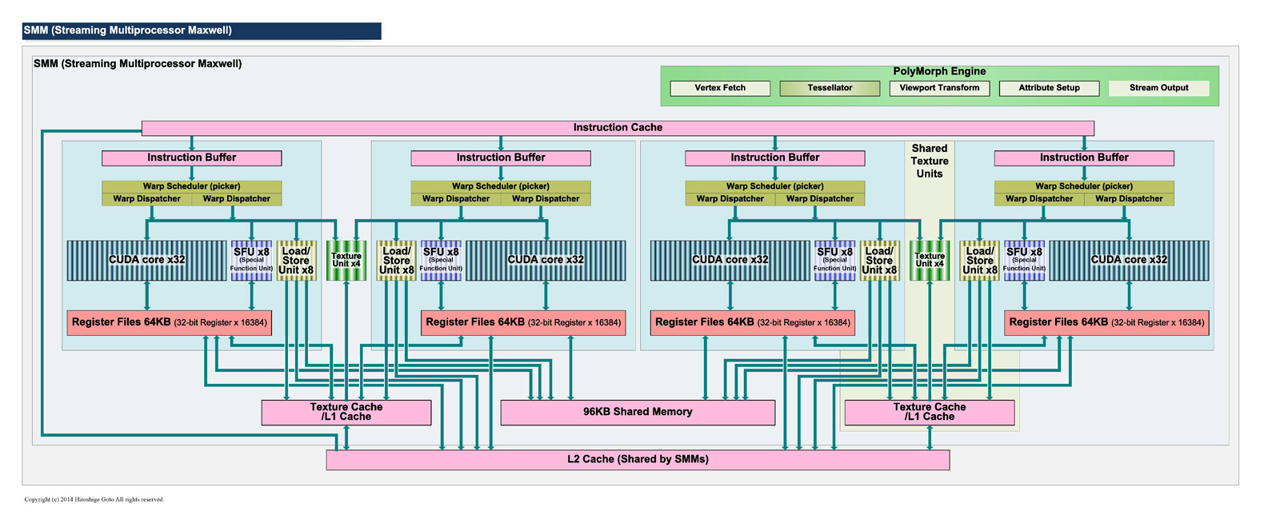
不管怎麼說 這樣改進還是脫離不了原先概念
CUDA 32個一組或許在DX11很吃香 DX12 1+31能夠Work嗎?
跑的快嗎?會比兩隻老虎還要快嗎

------------
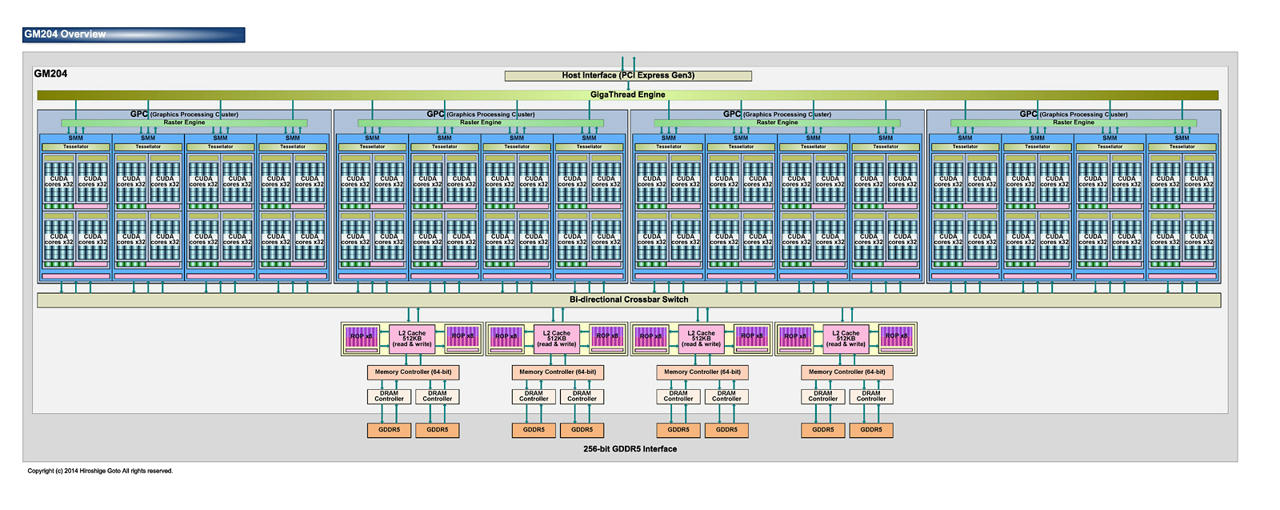
Shader Processors與Unified Shaders
兩個名詞的迥異其實道明設計方針的差異性
Maxwell, GM204
2048 Shader Processors 128 Texture mapping units 64 Render output units
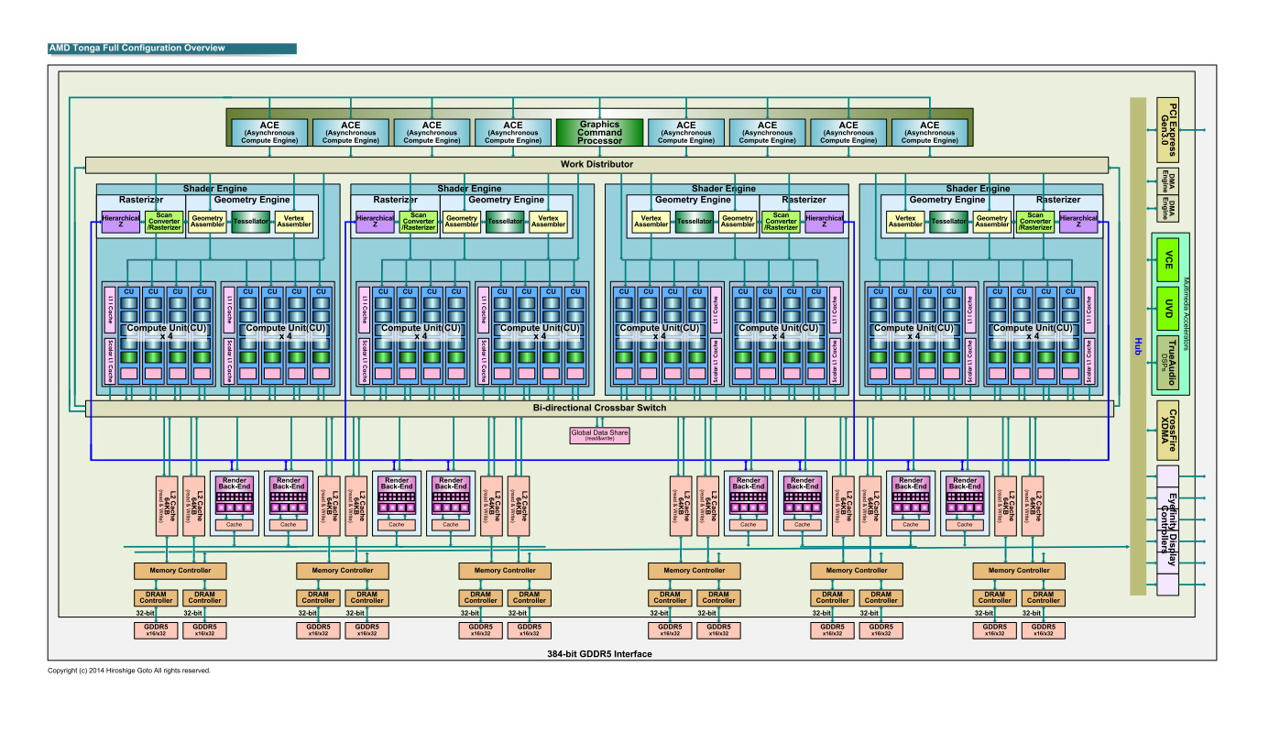
GCN 1.2, Tanga Pro
1792 Unified Shaders 112 Texture Mapping Units 32 Render Output Units
題外話 似乎看到有人在做這兩者的效率分析囉
比較令人納悶的是好像是AMD的人 這什碼情況

有點後悔今年買GTX 980...應該再等等
