引用:
|
作者orakim
已經說過了,不重複
自己倒帶看吧,說過的東西 還不知道錯在哪
那你的問題可不小
50/3
這是三個不同的測試放在一起,這樣隨便算也只是剛好
不過既然你自認為你的數學好,那先回頭看看你po的文吧
忘了回這段,補回
依你的計算推土機是有達到預期的K10 83%
那哪來的快X1100 50%,83%x8=X6 1100Tx150%?
83x8=664
600x1.5=900
看到問題在哪了吧,要達到你的150% X6 1100T
至少推土機每一個核心運算能力都要是K10的110%以上
即便4M/8C跟2M/4C是一樣快,那距離你預測150%1100T也有近30%的差距
即便4M/8C跟2M/4C是一樣快,那距離你預測120%1100T也有近10%的差距
|
你忘了 把 Clock Speed 加回去 也就是 664*1.25 = 830 830 / 600 = 1.383
也就是 4.2GHz 的BD會比 3.3 GHz X1100 快 38%
你數學真的不好阿

放心~我也沒好到哪裡去
我的算法瑕疵很大的∼因為我沒有估算模組與模組溝通的Overhead
所以現實上~ 假設 X1100 = 600 , BD 一個模組 = 160
4個模組 會是 160*4*overhead (基本上看軟體最佳化程度) 所以一定小於 640
不果整體的概念基本上是正確的
還有那個測試....真的不要凹了 除非是故意的(當然現在看回去非常有可能)
請問你不同處理器Benchmark 只靠比例怎麼比較 ? 沒有base怎麼比?
所以就算是3個測試∼ 他也是數據化之後加總
所以X1100 三個測試跑得分是100分的話
BD 就會是 150 分
這樣計分準不準確~~當然不準確~~但是有沒有算錯?沒有
我可以同意這種計分方式完全無意義,但很遺憾∼該網站沒有說錯 是50%
如同我之前幾篇回的 BD的架構上沒有問題,事實上我認為接下來Intel 一定會跟近
但事實上很糟糕是事實
模組化的好處是什麼?除了可以Die size的優點以外
最大的好處就是在多執行緒的環境底下,模組中的執行緒可以很快的相互切換資源
這也是為什麼Bulldozer 如此糟糕
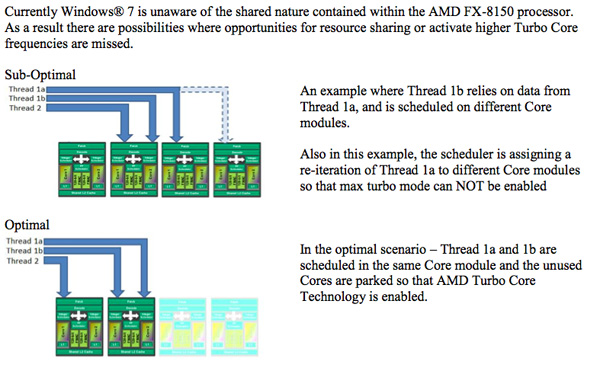
在目前Window7的情況 會製造出許多 BD 效的的 Worst case
1. A thread1 跟 A thread2 會被擺在不同模組
2. (Maybe) Race condition with Shared FP unit
3. Pipeline impact (cache miss, Branch prediction fail
這也就是為什麼 同樣四個執行緒 4M/4C 表現最好 4M/8C 次之 2M/4C 最糟