消息來源
Radeon HD 6900系列終於發佈了,不過頂著全新架構的光環,實際性能卻並沒有很多人想像得那麼好。難道真是新架構如此不夠力?其實說白了這才是一次真真正正的過渡,AMD以此為試驗品,正在為未來做著新的準備。
要理解AMD為什麼使用VLIW4 4D式流處理器架構設計,首先必須理解AMD為什麼使用VLIW5 5D式流處理器架構設計,而要回答後邊這個問題,又必須回到更遙遠的DX9時代,種子早在那個時候就已經埋下。
VLIW:超長指令字串(Very long instruction word),指的是一種被設計為可以利用指令級並行(ILP)優勢的CPU體系結構。一個按照順序執行指令的非超標量處理器不能充分利用處理器的資源,有可能導致低性能。
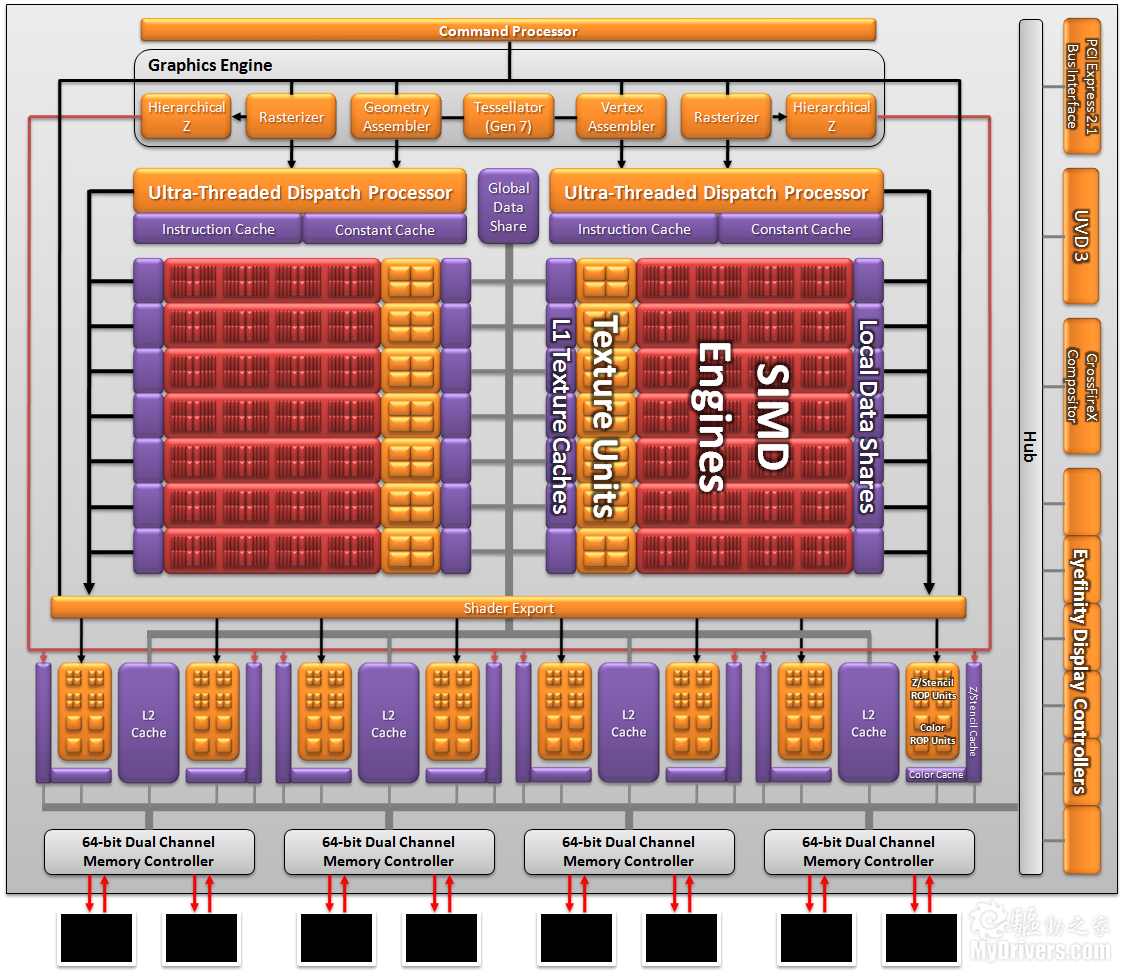
Barts Radeon HD 6800架構圖(Cypress 5800類似)
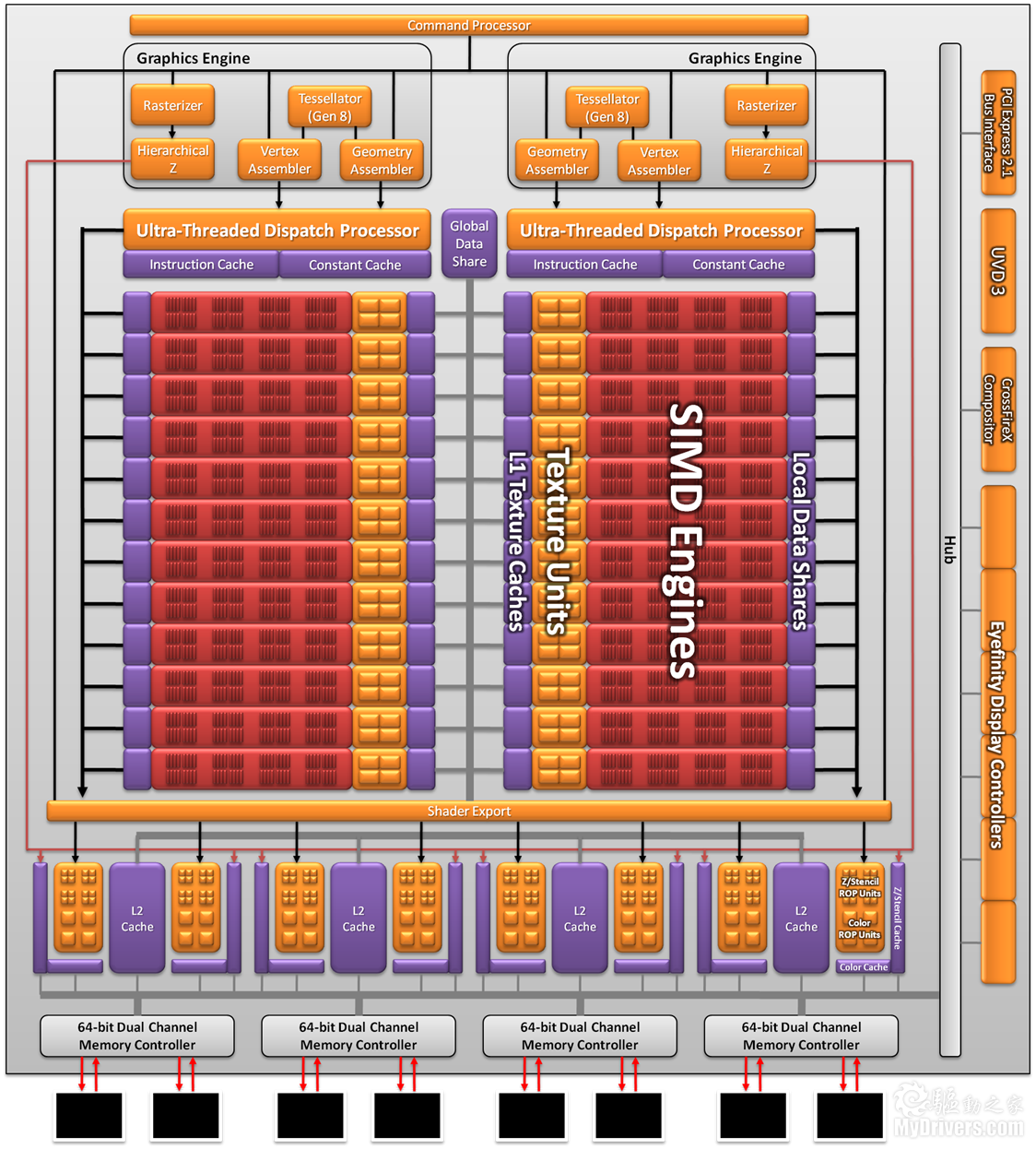
Cayman Radeon HD 6900架構圖
想當年著色技術還是新鮮事物,像素和頂點著色器仍是獨立的。以前ATI為他們的頂點著色器選擇了VILW5設計,因為ATI根據自己的數據得出結論,認為這是頂點著色器區塊的最佳配置,能同時處理一個四分量點積(比如w、x、y、z)和一個標量份量(比如光照)。
2007年,ATI發佈了R600架構的Radeon HD 2000系列,也是自己在PC領域首次引入統一著色架構,而且又一次使用了VLIW5。儘管這是DX10產品,但仍能很好地處理DX9頂點著色。GPGPU通用計算普及之前,這種架構適應得很好。

接下來進入2008年。顯卡廠商在規劃產品的時候一般都要考慮到兩年之後乃至更久的情況,所以Cayman Radeon HD 6900系列的設計那時候就已經著手了。當時GPGPU通用計算才剛剛起步,NVIDIA開始追逐的那個市場最多價值幾百萬美元,DX10遊戲也還沒有成型,但是AMD預測認為,通用計算將在兩年後(也就是現在)變得非常重要,DX9也會基本讓路給DX10/11,所以就必須提前重新評估VLIW5設計的優劣。
果不其然,GPGPU通用計算已經開始大行其道,Windows 7、DX10/11也正在將DX9擠下歷史舞台。根據AMD的內部數據,VLIW5架構的五個處理槽中平均只能用到3.4個,也就是在遊戲裡會有一個半白白浪費了。顯然,DX9下非常理想的VLIW5設計已經過時,它太寬了,必須縮短流處理器單元(SPU),重新設計裡邊的流處理器(SP)佈局。
AMD的顯卡核心架構非常依賴指令級並行運算(ILP),也就是將指令放在單獨一個線程內,和其他可以並行的線程沒有任何關聯。VLIW5下最理想的情況就是五個指令能夠在每個時鐘週期裡、每個SPU上一起調度執行,但這種機率非常低。按說平均使用3.4個已經不錯了,但換算下來還是不足80%,結果就是從工作負載種提取ILP非常困難,導致最好、最壞應用環境相差太多。
與之形成鮮明對比的是線程級並行計算(TLP),那些沒有任何關聯的線程也可以同時執行。這正是NVIDIA在高端核心上所依賴的設計理念,GF100/GF110都是借助TLP達到高效率的標量架構。
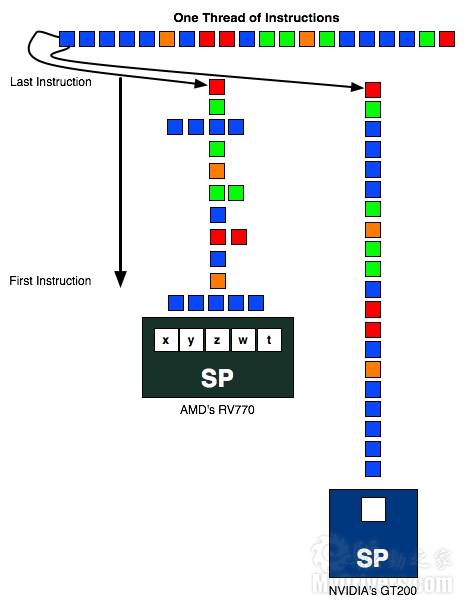
最終,AMD意識到VLIW5架構已經不適合繼續發展,必須針對未來準備一種新的高效率架構,不但要提高平均使用率(大於3.4個),還需要適應並行計算負載,結果就是轉向VLIW4。