PCDVDŒÆŠìŹì§Ț°QœŚ°Ï
(https://www.pcdvd.com.tw/index.php)
- štČÎČŐ„ó
(https://www.pcdvd.com.tw/forumdisplay.php?f=19)
- - AMD FXštŠC„X·s«~...
(https://www.pcdvd.com.tw/showthread.php?t=1057113)
|
|---|
> ŠA»ĄKaverišS€FHSAčêŠb·Q€Ł„XŠł€°»òœæÂI
> AMD,§ÚŻuŹO·d€ŁÀŽ§A°Ú :think: «ÜÂČłæŠ]Ź°HSA»ĘnOS žòłnĆéȘș€äŽ©; šSŠłłošâÓȘFŠè„uŠł”wĆé€]”„©óšSŠłHSA Č{ŠbšâÓłŁšSŠł ,ŠłšSŠłGPUźtȧ©Ê€Ł€j(€Ï„żłŁšSHSA) PS.łoÓšSłnĆé„i„ÎȘșȘŹȘpźŁ©È·|«ùÄò€@Š~„Ș„k(Ó€HČqŽú) > Šł HSA €@ŒËšSœæÂI°ÚĄA§Úı±o HSA ŠbŹìŸÇčBșâ»â°ì€~€ńžûŠł”oŽ§ȘƶĄ > GPU ŹÛžû©ó CPU ȘșÀu¶ŐŠb©ó GPU ŠłŹÛ·í€j¶qȘșčBșâłæ€ž > ©Ò„H„ȶ·„á„i„H°Ș«Ś„Šæ€ÆȘș€u§@”č GPU pșâĄAłoźÉ GPU ȘșÀu¶Ő€~·|źiČ{„XšÓ §AÁżȘșłołĄ€ÀŹOčL„hGPUčBșâȘș€èŠĄ,ŠęHSAžò„LŠłźÚ„»€WȘș€ŁŠP „H”{ŠĄšÓ»ĄčBșâ€èŠĄ„i„H€ÀŠš„i„Šæ€Æ žò€Ł„i„Šæ€Æ čL„hšÏ„ÎGPUȘșčBșâ„i„H»ĄŹO§č„ț„Šæ€Æ,CPUšSŠł€¶€JčêœèčBșâ §Y«KCPU€¶€J€]Š]Ź°©”żđčL°Ș ÀWŒečL§C ŸăĆéźÄŻàźt,žòŻÂCPUčBșâšSŠł€Ó€jźtȧ(©ÎŞ̦óșC) ©Ò„HŹĘ€ŁšìCPU+GPUłoșŰÀł„Î€èŠĄ §č„ț„Šæ€ÆȘșčBșâ€èŠĄ,Šb€@ŻëšÏ„ÎȘÌÀôčÒ«Ü€ÖšŁ; čê»Ú€W€Ł„i„Šæ€ÆȘșčBșâŠû€F€Ł€ÖłĄ€À (ŠęÁÙŹOŠł„i„Šæ€ÆčBșâȘșłĄ„śŠsŠb) HSAł]pȘș„ŰŒĐŹO„i„Šæ€Æ”čGPU €Ł„i„Šæ€Æ”čCPU ĆęCPU GPUŠUŠÛtłd„LÌŸAŠXȘș€u§@,čę©łžŃšMčBșâ€WȘșČ~ÀV łoŠbčqžŁ„v€W«Ü©úĆăŹO€@łő«e©Ò„ŒšŁȘș€jČ©R (€W€@ŠžČ©R«Ü„©€]ŹOAMD±È°_Șș:AMD64) Żà€ŁŻàŠš„\ŽNŹĘAMDŻàŒőŠh€[,łnĆéŹO»ĘnźÉ¶Ą„h°ï„XšÓȘș > AMD±q€@¶}©lŽN€ŁžÓ±ÀšâÓ„„x y > žêȘśĄB€H€O»Pčï€âȘșźt¶ZÄaźí €ŁčL§A«á±Șș”oš„Šü„G„Hsocket°Ï§O„„x ŠÓ§Ú»{Ź°ȘșšâÓ„„xŹObulldozer,bobcat łošâÓŹ[șc„X”oÂIŹÛŠP,„uŹOčêČ{€èŠĄČ€·L€ŁŠP;ŽNłÌČŚ”ČȘGŠÓš„ šâÓ°őŠæźÄČv«D±`±”Șń čêŠbšS„ČnŹ°Šč¶}”ošâșŰŹ[șc > „DŸśȘOȘșšŃčqŒÒČŐšșŽNčL€Ł€FĂö > Ź[șcĄB»s”{šSÂœ·s¶išB > APU«ÜĂűčFšìR7-260Șș€ô·Ç šäčê§A§Ń€F€@„óšÆ,DDR3°OŸĐĆéÀWŒe€Ó€p; §Y«K¶ëÓR7-260šșŒË€jȘșGPU¶i„h,”oŽ§„XšÓȘșźÄŻàžòA10 7850K €]€Ł·|Šł€Ó€jźtȧ €]„uŠłčłPS4šșŒËštČΰOŸĐĆé±ÄGDDR5 €~Żà”oŽ§GPUȘș·„ ©ÎŞ̦A„i„H€ÏčLšÓ·Q,AMDŽNŹOŠ]Ź°°OŸĐĆéÀWŒe°ĘĂD€~ł]pšșŒËȘșGPU |
HSA§Ë±o°_šÓIntelŽN·|§ËÓ«ÜčłȘșȘFŠè„XšÓ :p
·PıAMD«ÜčłIntelȘșčêĆç«Ç 3DNow!->SSE Cool'n'Quiet->SpeedStepźłšìźà€W«ŹCPU K8 CPU€ș«Ű°OŸĐĆé±±šîŸč->Intel NehalemŹ[șc HyperTransport->QuickPath AMD64->Intel64(ŽNŹOŠł€pŠa€èžò§A€ŁŹÛźe) PhenomŠ@„ÎL3Ź[șc->NehalemŹ[șcžò€§«áȘșCore SSE5->AVX APU->CPU€ș«ŰĆă„Ü |
€Ț„Î:
AMD„h±ŽŻÁ„t„~€@±űžôĄA ”M«áIntelŠA„Ξ규ÀŁčL„h... :laugh: |
NintendoFamicomȘș”oš„Ćę§Ú·Qšì€@„óšÆ
ŠpȘGŹO„HHSAŹ°«eŽŁȘșȘŹșA€U,GPUȘșcompute unit nŽXÓ€~ŠEșâ (Š]Ź°HSAčBș⊳·„ šì€@©w”{«Ś źÄŻàŒW„[«ÜșC) °Čł]€@Ó compute unit€U,GPUȘșźÄŻàŹOCPUȘș€Tż 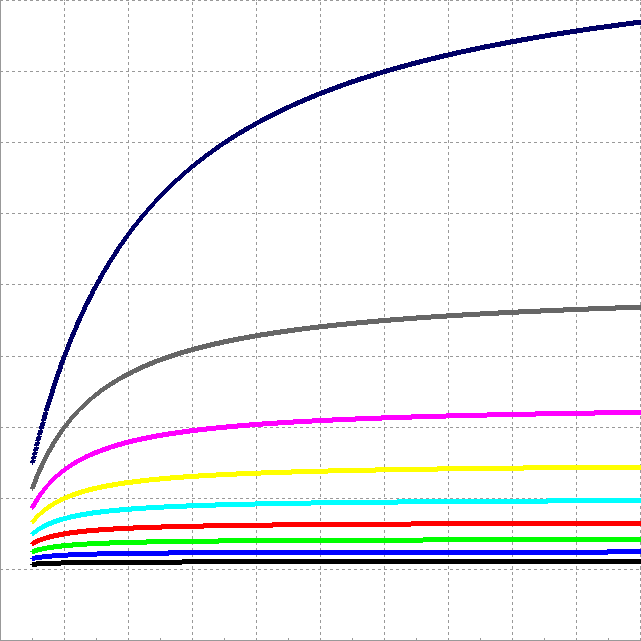 Ÿî¶bŹOGPUȘșcompute unit(¶Ąčj2),Áa¶bŹOźÄŻà(¶Ąčj1) ĂCŠâŹO„i„Šæ€Æ”{«Ś(¶Ąčj10%)_80%(ŠÇŠâ) 70%(Źő””) 60%(¶À) ŠpȘG„unšDHSA”{ŠĄ žòintel ŻÂCPU źt€ŁŠh§Ö, „H„i„Šæ€Æ40%(Źő)šÓ»Ą 1ÓCPU °t€W2Ócu(4ÓCPUŽNn8Ócu) <-ło€ńšÒèŠnŽNŹOA10-7850K ŠpȘGÁżšDŠEșâȘșžÜ,„H„i„Šæ€Æ50%(żĂ„úÂĆ)šÓ»Ą €j·§CPU:GPU=1:4 «Ü©úĆăA10-7850K GPUȘșcu €Ö€F€@„b ŠpȘGnžÉșĄło€@„b Ž«ŠšAMDȘș»ĄȘkÀłžÓŽNŹO20źÖ€ßȘșAPU (CPU:GPU=4:16) |
€Ț„Î:
łoŒËȘșžÜĄAAMD ȘșłBčÒŽN§ó„[Á}Ăű€FĄAŠ]Ź°”{ŠĄ€ŁŠęnŸăÓ«ŒgĄAŠÓ„B«ŒgĂű«Ś€jŒWĄAŠ]Ź°ÁÙn€À§O€ÁłÎ€u§@”č CPU ©M GPU ŠA»ĄČ{ŠbȘș CPU €]šŹ„HÀł„I€@ŻëÀł„΀FĄA€u”{źvźŁ©È€]€ŁÄ@·NŹ°€F€äŽ© HSA «Œg Code.. ·QŠAœĐ±Đ€@Ó°ĘĂDĄAšșŽNŹO CUDA 6 €äŽ©Č΀@ŽM§}ĄA€]ŽNŹO»Ą GPU ©M CPU ÀłžÓ·|Š@„Î CPU Memory (Main Memory) Šę CPU ·|ŠP·NĆę GPU °Ê„Š„DșȚȘș CPU Memory ¶ÜĄHCUDA 6 ȘșČ΀@ŽM§}šì©łŹO«ç»òżìšìȘș°ÚĄH :confused: |
n±ÀHSA
§Ú»{Ź°łÌłÌ«nȘșŹOAMDnźł„X€@ÓČ©R±ț€âŻĆȘșÀł„ÎłnĆé 賏OÂàÀÉ AMDYŻà§äšìŒt°ÓŠX§@ĄA”耩łnĆé¶}”o€äŽ© ŻàĆęA10-7850KȘșHSAÂàÀÉ źÉ¶ĄÁYšìi7 QSVȘș€@„b ”eœèŹOŻÂCPUčBșâȘș€ô·Ç łoŒËšä„LÂàÀÉłnĆé„ŒšÓŽN·|€Ł±o€Ł±À„X€äŽ©HSAȘșȘ©„» «ÂIŠb©óČÄ€@ÓŸŠœün«ç»ò„h±À°Ê„Š...... |
€Ț„Î:
€ŁȘŸžòboinc€§ĂțȘșŹìŸÇčBșâ”ČŠXŠłšSŠł·dÀY ©ÎŹOŹYšÇčłPCB LAYOUT€§Ăț»Ęn±j€jpșâ€OȘș (€ńŻSčô?) |
¶VšÓ¶VČ`¶ű€F.....ŹĘ€ŁÀŽ... :stupefy:
|
> ŠA»ĄČ{ŠbȘș CPU €]šŹ„HÀł„I€@ŻëÀł„΀FĄA€u”{źvźŁ©È€]€ŁÄ@·NŹ°€F€äŽ© HSA «Œg Code..
ŠłŠhȘșźÄŻà„XČ{ŽN„i„HŠł§óŠhÀł„Î€èŠĄ„XČ{ ŠÓ„BźÄŻà»ĘšD±qšÓšS€ÖčL,Č{Šb€Ł«Œgcode „ŒšÓ€]n«Œg „t„~HSA€]€Ł„ušîŠbx86€W,ARM€]Šł(AMDčwp©úŠ~·|±ÀȘșskybridge framework) > Šę CPU ·|ŠP·NĆę GPU °Ê„Š„DșȚȘș CPU Memory ¶ÜĄHCUDA 6 ȘșČ΀@ŽM§}šì©łŹO«ç»òżìšìȘș°ÚĄH :confused: ¶ÇČÎŹO€Ł·|ŠP·N(Šw„ț©Ê°ĘĂD) CPUŻàłBČzȘșĆvžòGPU€ŁŠP žêźÆł»Šh„uŻàłæ€èŠV¶Çżé CUDAłzčL§óŽ«CPUšçŠĄźwȘș€èŠĄ,ĆęĆv€ŁŠPȘșŠw„ț©Ê°ĘĂD±ošìžŃšM łzčLłnĆé€èŠĄ ±N„H©čcudan€H€ułBČzȘșłĄ€ÀĆę„Š„i„HŠÛ°Ê°őŠæ ŹÙ±ŒłÂ·Đ ŠÓAMD€è±€§«eŠłŒgčL(Šb€U±łoĂä) http://www.pcdvd.com.tw/showthread.php?t=1028634 „t„~€”Š~€@€ëAMDŠłŽŁšì€@„óšÆ, „L€Ł„unŠb°OŸĐĆéčêČ{łoșۧȚłN „ŒšÓłscache€]n°”šìłoșŰÂùŠV·Ÿłq „Ű«eȘșkaveri Šbcache€è±ÁÙŹO„uŠłłæŠV¶Çżé(„uŠłGPU €~„i„H±qCPU cacheźłžêźÆ) AMDŹO»ĄŠ]Ź°cache ÂùŠV·ŸłqȘș§ȚłNčL©óœÆÂű·|©ìšìkaveriȘș€W„«,©Ò„H©ń±ó€FŠę„ŒšÓÁÙŹO·|Šł > §Ú»{Ź°łÌłÌ«nȘșŹOAMDnźł„X€@ÓČ©R±ț€âŻĆȘșÀł„ÎłnĆé > 賏OÂàÀÉ łoŹO€@©wȘș,AMD pptžÌŽŁšì€@ÓHSAŒt°Ó ŽNŹOŠb§Ëx265 „i±€x265„Ű«e”oźi€€ ”eœèÁÙ€ń€Ł€W«ÜŠšŒôȘșx264 °Čł]x265čFšìČz·QȘș”eœè ŠłžŐčLx265ȘșÀłžÓȘŸčD„LŻuȘș«ÜșC, €Ł·|Šł€H·Q„ÎŻÂCPUšÓ¶]4K videoȘșx265œsœX,€@©w·|±ÄšúŹYșŰ„[łtȘș€èŠĄ |
€Ț„Î:
èŹĘ€F€@€U Unified Memory in CUDA 6ĄAžêźÆŠü„GÁÙŹO„ȶ·Šb GPU »P CPU €§¶Ą·hšÓ·h„hĄA„uŹO€§«e„ȶ·€â°Ê·hČŸĄAČ{ŠbŠł€F managed memoryĄAštČη|ŠÛ°ÊÀ°§A·h ·PıŠłÂI賏O"Șí±€WȘșČ΀@°OŸĐĆé (Unified Memory)"ĄA„uŻà„Κӎ”{ŠĄ¶}”oȘÌȘștŸá„H€ÎĆę”{ŠĄœX€ŁŠAšș»ò€ŸÂŰ (€Ł·|ŠAŠł€@°ï cudaMemcpyXXXXToXXXX() €F) CUDA „H«áŠł„iŻà°”šìȘœ±”ŸȚ§@ CPU MemoryĄA€Ł„ΊA§âžêźÆ·hšì GPU Memory ¶ÜĄH §ÚŠb·Q§Y«K„i„HĄAŠę GPU Âś CPU Memory šș»ò»·ĄAłoŒËčBșâłt«ŚŻuȘș§Ö±o°_šÓ¶ÜĄHŠpȘGŻuȘș§Ö€Ł°_šÓĄAšș CUDA ŹO€ŁŹO«eŽșłôŒ{€F°Ú (ŹÛžû©ó AMD Șș HSA) :stupefy: |
| ©ÒŠłȘșźÉ¶Ą§ĄŹ°GMT +8ĄC Č{ŠbȘșźÉ¶ĄŹO03:24 AM. |
vBulletin Version 3.0.1
powered_by_vbulletin 2025ĄC